In version 5 we will be introducing a new supporting data service - shared memory. From a technical standpoint, the shared memory is centralized key-value storage that is physically located in the same repository where data connectors are stored.
If you're not familiar with the concept of key-value storage, you can think of it as a Windows registry where values are stored by a certain path (key).
At this point, there are 4 operations that can be done with the shared memory:
Remember
Recall
Forget
List
The operations are performed using the new "Shared memory" action. It has 4 respective commands:
Remember
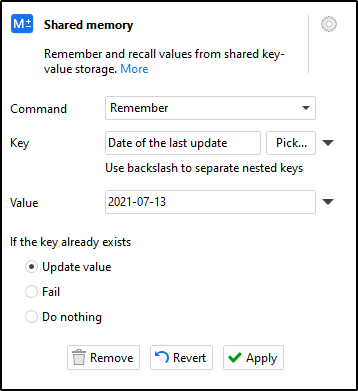
Remember (store) a value by associating it with a key. For instance:
Key is "Date of the last update"
Value is "2021-07-13".
A key can be composite, for instance, "Database\Customers\Date of the last update". Composite keys are separated with a backslash.
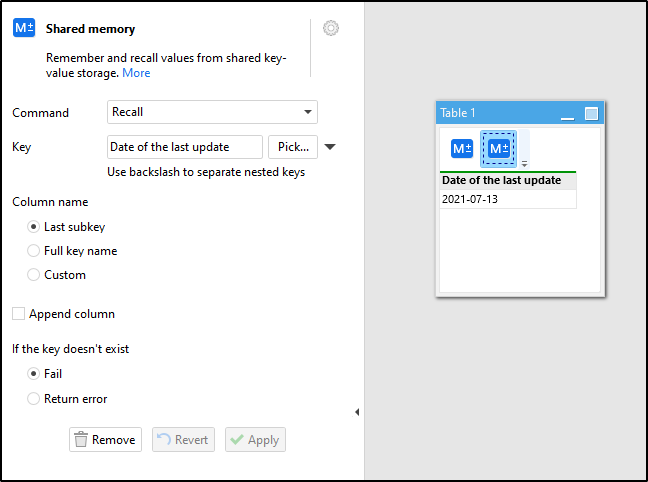
List all keys that start with a given substring, and their associated values.
Use cases
The shared memory can be convenient in many cases:
Store temporary values - E.g. store the last loaded date when doing incremental loads.
Pass values between workflows and users - Similarly to the shared connectors, the shared memory can be accessed from different Desktops. Once a value is remembered, it can be accessed by all Desktops and Server spaces that use the same repository
Environment configuration - The shared memory can be used to store configuration settings that are different in PROD and TEST environments.
Workflow variable - While project parameters are constant and don't change during a workflow run, the shared memory values can be set, removed, and changed in a single workflow
Lightweight data store - Sometimes, using a relational database to store and share just a few values looks like overkill. The shared memory can be more appropriate for such cases.
Features
Access restriction - the same access restrictions as for data connectors apply
Concurrency - the shared memory supports simultaneous operations from different computers
EasyMorph data types - values are remembered and recalled in exactly the same data types as in EasyMorph - number, text, boolean, empty value. Errors can't be remembered by design.
Big values - you can store large text objects, such as JSON in the store
Very interesting.
I guess these Keys will be shared over all the projects.
May I suggest to add a few automated attributes, mainly for compliance purpose, like updated date, updating project, updating user, owner. All these attributes in read only mode of course.
And maybe operations like 'Deactivate' that would be like 'Forget' but keep a track of the value and 'Freeze' to switch it to read only mode, 'Unfreeze' could be done only with the same owner (and from the same project : not sure, too restrictive) . This way a projects supervisor could handle central parameters, environment configuration
Columns with the last updated time and updating user will be seen in the List mode.
Freezing (locking) is an interesting idea - something to think about.
Further development may include a TTL (time to live) after which a key is erased automatically. This would simplify designing caching strategies.
Another idea is adding queues to the shared memory with the ability to push values into a queue, and pop values from a queue. This would simplify building "consumer-producer" type of automation.
All in all, we're preparing EasyMorph for heavy enterprise use in massively parallel workloads.
With giving a little thougths about it, it's a very powerful feature.
Especially if we consider they can be composite.
But the management of these central parameters could be complex.
Could we have a tab and a toolbar dedicated to the overview of these key values instead of a pop-up view unlike the one for parameters.
As they can be composite, the navigation could be done with a treelist on the left pane and a detail pane on the right like the advanced view for parameters ?
Yes, we will be adding a tab in the Connector Repository Manager (in Desktop) for browsing the key-value storage and modifying keys and values (if permitted). But not in the very 1st release, a bit later.
Also, we will be adding Server API methods for working with the key-value storage. It will make it possible for external applications to set/update/remove values in the storage remotely and programmatically. For instance, an external system will be able to set/remove a flag to signal EasyMorph projects that they can or can't access the system (e.g. during high load periods or during migration).
Under the hood, it's an encrypted SQLite database, so it's quite permissive. The shared memory can theoretically hold millions of keys with values as big as several megabytes of text each.
The max key length is appr. 260 characters in the URL encoding.
In our tests with rather short text values, the shared memory could process a few hundred requests per second, given small network latency. However, with larger values, the request performance will likely go down due to encryption overhead.
The shared memory is great, I love it.
Is there is a way to edit them manually.
I tried to use dbgate for that (https://dbgate.org/) but as the database is encrypted, it led me nowhere.
The Connector Manager in Desktop will eventually make it possible to view and edit entries in the Shared Memory. Also, the Server will have a Shared Memory API.
I'm curious what are your use cases for Shared Memory?
... just trying the Shared Memory for the first time .... how do I flush all entries in the memory eg. all keys under 'Keys\BatchedOrders'? There are 1.200+ entries which seem heavy to delete/FORGET one-by-one...