Continuing the discussion from Data quality on keep mismatch:
When there is a need to go through all columns of a dataset, one by one, here is how you can do it:
- Generate a list of columns in the dataset.
- Use “Iterate table” to iterate across the list and pass each column name together with the original dataset into a subproject.
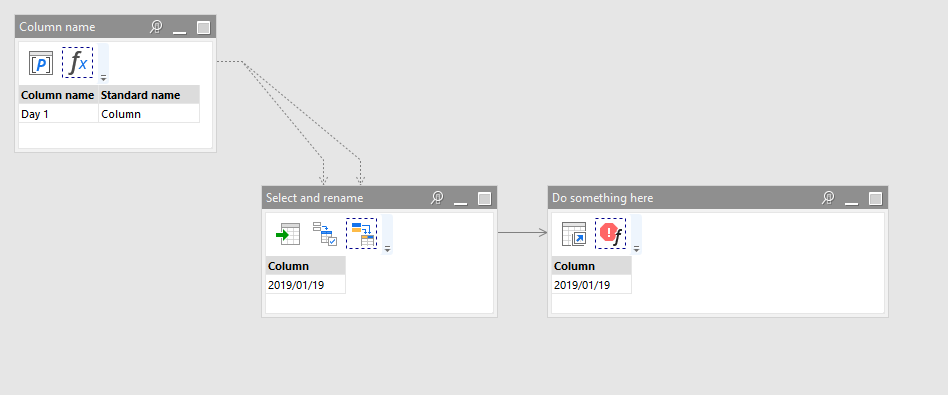
- In the subproject, use the “Input” action to obtain the dataset itself, and a parameter (e.g. “Column name”) that will be assigned to each column name in the iterating (parent) project.
- Now, in the subproject you have the dataset and a parameter that tells you which column to process. Use the “Select with lookup” action to select only that column.
- To use expressions we need that the column always has the same name. Therefore, use “Rename with lookup” action to give the selected column a standard name, e.g. “Column” or “Data”. Now you can use an expression with
[Data]that will be applied to all columns of the original dataset.
See the example below.
iterate-columns.morph (3.6 KB)
column-action.morph (2.9 KB)
The example generates a table with sample data. Then it produces a list of columns in that sample data, and calls subproject column-action.morph once for every column name, passing the name and the dataset into the subproject.
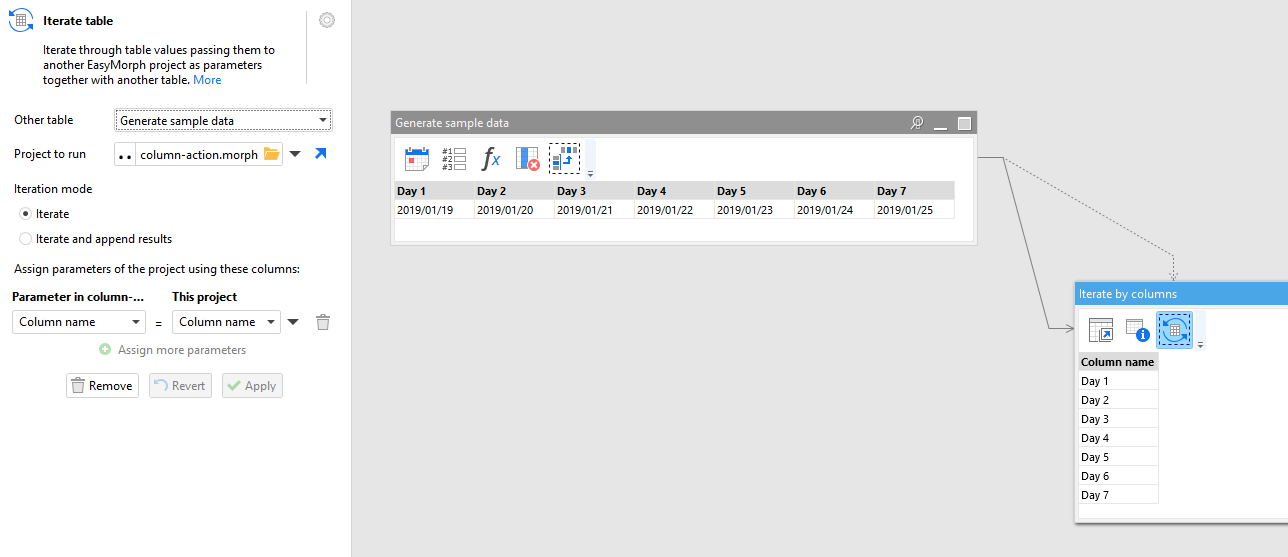
The subproject singles out the column which name is specified by the project parameter, and checks whether this column has non-text values.