I query a database every 20 minutes. It is an MS-SQL database. It puts a strain on the system that can affect users. I am pulling 13 months of CRM history to build reporting. There is a field LastUpdated that shows the date/time for every record.
I want to run the main query, 13 months data, then from that point on do only an append query, grabbing only new records since the last run. I think this means creating a parameter for LastRun using the Now( ) function, and then doing an SQL query that only looks at records where the date/time of LastUpdated is greater then the value in LastRun.
The report is a rolling 13 month report, so I want the main "bulk" of the query to update 1x a month to the prior 13 months and then query the newest LastUpdated records.
If someone can guide me and show proper syntax - especially for parameters - it would be greatly appreciated as I think it would remove a huge load off the server resources.
Hi,
What you are describing is commonly known as an "incremental load". The steps you described, using parameters and somehow storing the last run time is pretty much exactly how it can be implemented in EasyMorph. There are some very important details though which if you don't get right can mean it never quite works perfectly, so let's break it down.....
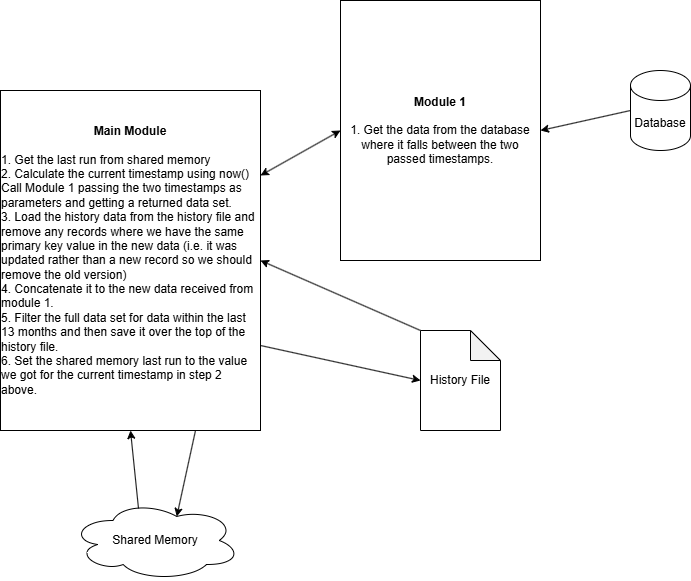
You need to have a few things, the first of which is a mechanism for storing the last run timestamps (e.g. a text file, a DB table or an EasyMorph Shared Memory Key). You also need to have a way of storing the data which you extract and composite back together (e.g. one or more CSV files, a separate database, etc) which I'll refer to as the cache. Your database table must have a primary key field which is unique for every record. And of course the LastUpdated field which is 100% accurate (more on this later).
Then you can build an incremental process which follows the following steps each time it runs:
Get the timestamp of the last run from wherever it is stored. If it isn't there, then I need to generate a timestamp that is far enough in the past to ensure it is before any LastUpdated value. Which ever is the case, this becomes my "From" timestamp.
Record when this run was started using now() and this becomes my "To" timestamp. You might think I don't need this and I can just load where LastUpdated > From. But doing this gives a possibility for records to be missed if they are changed during the time it takes for one of the incremental load runs.
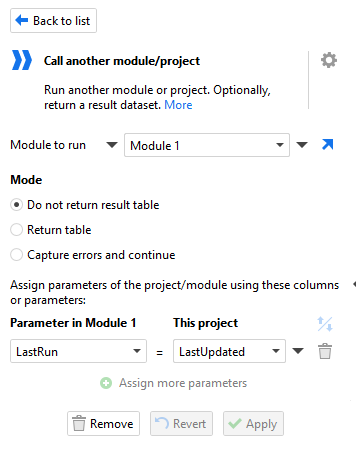
Call another EasyMorph module, passing it parameters for the From and To and getting back the newly updated data. Extract the data from the database where the LastUpdated > From OR LastUpdated <= To. Note that the > and <= are important. If you had them as >= and <= or even > and < then there are opportunities for records to be missed or double counted if they fall exactly on the From or To timestamps.
If I'm doing a full load (where the From is set to a date far in the past, this step can be skipped. Get from the cache any data where the primary key value doesn't already exist in the data loaded from the DB and concatenate it together to create the new version of the data. This is important to ensure you don't get more than one version of the record.
Save the new version of the data to the cache overwriting the previous version.
Set the stored timestamp of the last run to be equal to the To value from this run so that next time it we know when we last run. It is important to set this to the To value from the start of this run rather than using now() again. If this execution too a minute to perform, then that is a minute for records to be missed.
I've created an example of this process, which uses an EasyMorph Shared Memory key to store the last run timestamp, passes it to another module "Get updated data" with 2 parameters for the From and To values which extracts the new data set, then combines it with any previous cache (an EasyMorph dset file) after checking if one exists by calling the module "Check if cache exists". Hopefully it will help you to see how it can be done and you can adapt it to your own specific use case. Its a fairly robust example which includes checking if a cache file and the shared memory key already exist. It also has parameters for what the cache file should be called. The Modules "Manually set the last run time" and "Update some records" are only there for you to run manually to update or remove the shared memory key or to update/add some records in the DB. I've added annotations to try and explain parts so hopefully it will make sense. Although it is fairly robust, it doesn't cover everything that can catch you out in an incremental load (see below).
One important thing worth noting, is that in the real world, incremental loads can be incredibly complex to get right, with lots of important caveats and requirements, some of which I've hinted at above. By right I mean that after it run, the data set it creates matches that which you would get if you just loaded all of the data from the DB. Another important problem (which I've learnt the hard way more than once) is whether or not your "LastUpdated" field is always updated when a record is changed. I've worked with lots of companies who found that after implementing an incremental load, the composite data set slowly diverged from the data in the database over time. They needed to perform a full reload of the data to get it back aligned. This is almost always because there is some scenario that updated the record without updating the LastUpdated field (e.g. a piece of code in the system, a stored procedure in the MS SQL DB or even a user performing update queries).
Thanks for sharing an example. It really helps. I will try this today or tomorrow and share the outcome. The community platform really is the way to go into sharing insights. I will review the ODBC case sent over. Really appreciated.
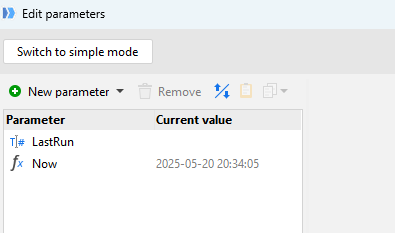
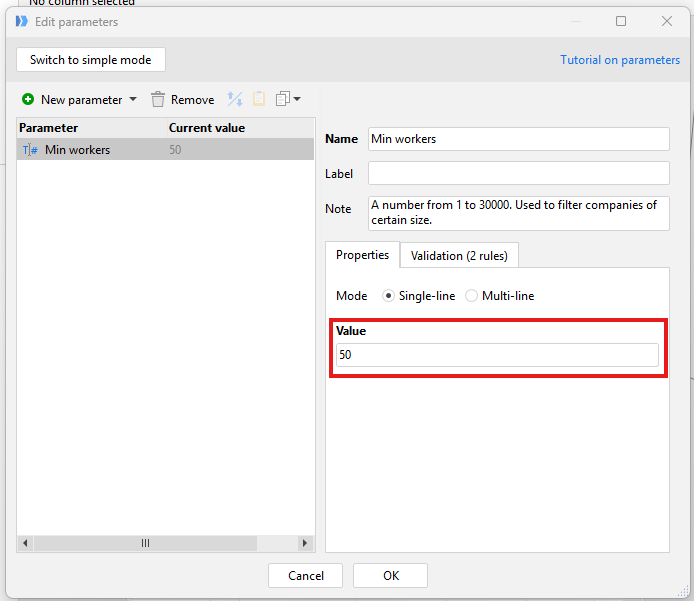
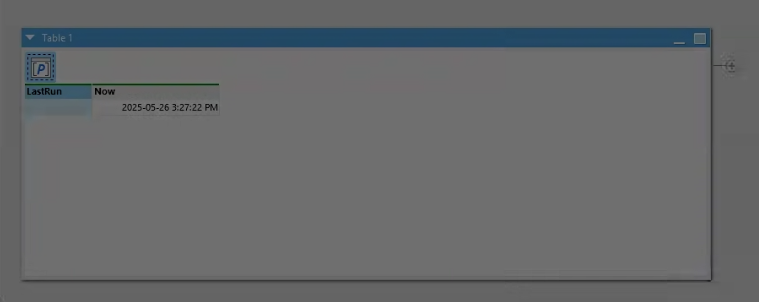
Last Run Parameter table in Module 1 is not receiving the call from Main Module to populate the LastUpdated timestamp into the LastRun parameter in Module 1. The parameter for LastRun, which should be based on the first value of column LastUpdated in Main, stays blank. In previous cases, sometimes a parameter updated and then populated the right info, but I can't get this to do it .
Why do you think LastRun parameter in Module 1 is not being updated with the info from Main - LastUpdated. Should I put a blank calculated field or date field? I tried those but they didn't work.
I also tried to give LastUpdated its own field name in case the Call Module function would grab it from Main module first data table before it was transformed into a single cell column with Max function in the derived table.
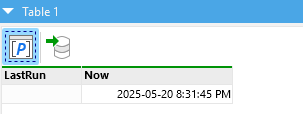
I think the issue is when you view Module1 you are expecting to see the LastRun parameter show the value passed from the Main module. Unfortunately this isn't how it works, which caught me out too at first. The main reason being that as well as the Call action, there are iterate actions which call a module many times passing different parameter values each time.
Its a bit tricky to explain but here goes....
Your LastRun parameter in Module1 will only have the value passed from the Call action in the Main module for the brief period of time it takes to run and return the result. For this reason, you when you view Module1, you will see LastRun containing the default value you assign to the parameter when creating or editing it.
To test Module1 is getting data only from a certain timestamp onwards, set a default value of LastRun and then run all Module1's actions. Once happy it works as expected, you can then test the parameter passing by going back to your Main module, and change the Call action to return the data set from Module1.
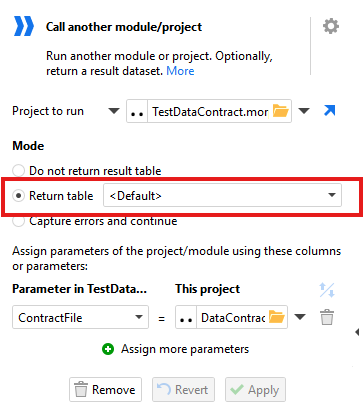
Note that if you haven't flagged a default result table in Module1 you will need to, or specify the table you want in the dropdown.
When the Call action is then run, you should see the data returned and you can check that it only includes the records you expect based upon the LastUpdated value that was passed.
Hope that makes sense, its a tricky one to explain in writing.
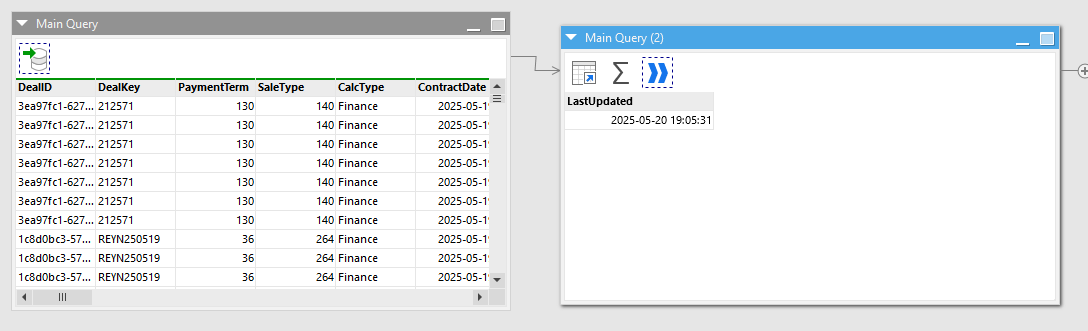
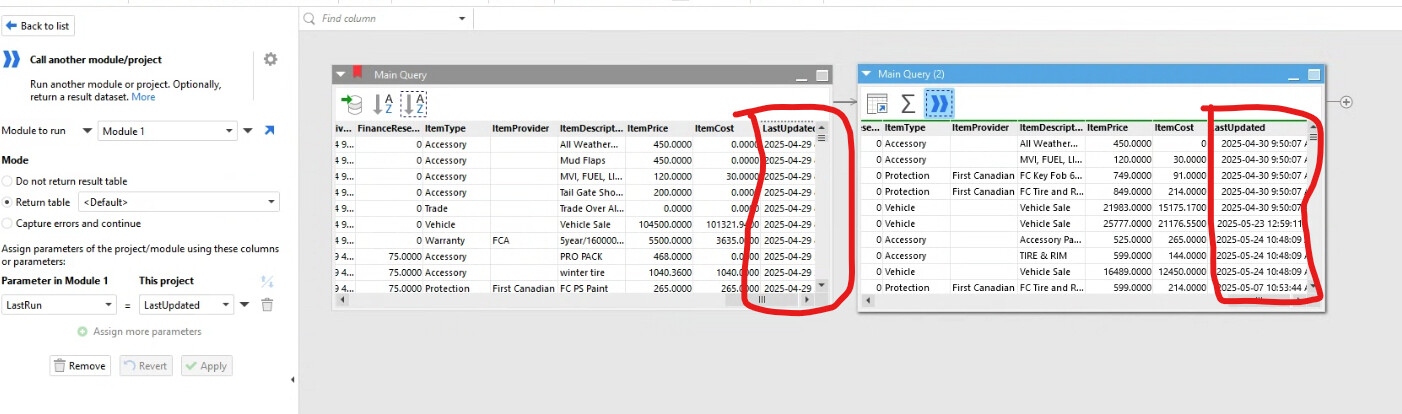
The return table function brings data back into a second table in the Main module. It shows the records that are since the last update, but it is dependent on the main query, and the main query looks like it runs again, which defeats the purpose. See main module.
run a query against 1 table in MS-SQL database. Pull all records where ContractDate is 13 months or less. Call this Main Query.
run a second query with records whose LastUpdate is greater then the LastUpdate in the table from step 1 (call this LastRun - create a parameter with it if possible to use in a query where LastRun is greater then LastUpdated.
Append the net new records to the Main Query output from the initial table WITHOUT re-running the main query.
Export this combined output every 15 minutes to a google sheet.
At this point, unless I have exact actions, I don't know how to make this work! We tried many combinations.
Module 1 is below.
Hi Community? Any guidance would be appreciated. We cannot even figure this one out with ChatGPT, Gemini or Claude. Looking for some human intelligence!
From what I can see from your two screenshots, in your main query you seem to be loading the data from the database and then calling module 1. I wouldn't expect this to be the case, and if you check my example .morph above you'll see that the main module doesn't load from the database at all. Additionally your module 1 seems to just receive the parameters and not do anything with them.
Here's a very quick diagram of the modules, what they interact with and the basic steps to perform an incremental build: