Hi,
Part - 1
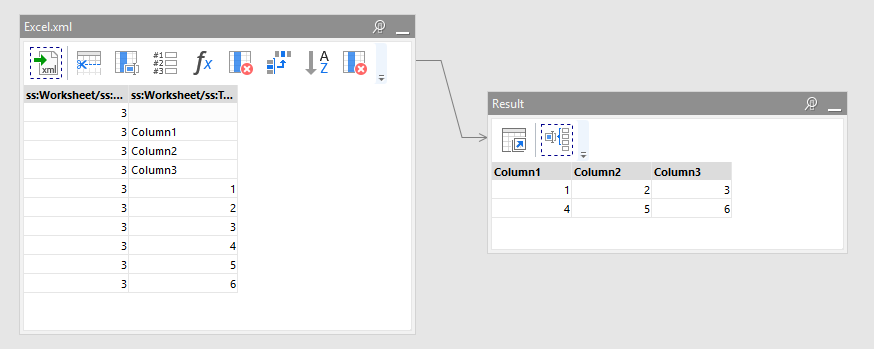
What is the best way to process and XML file such that you can determine Column Names from one set of Elements and the Data from another set? I am assuming multiple derived tables. But if you assume the following sample, I am curious as to the ‘cleanest’ way to break on each new Row and then ‘pivot’ each set to form columns. This is not a real-life scenario but a solution here may help me with XML formatted files in general.
I have tried a few different techniques and I am sure that I could hack something out but wanted to hear how other’s may have tackled the same format.
<Rows>
<Row>
<Column>Column1</Column>
<Column>Column2</Column>
<Column>Column3</Column>
</Row>
<Row>
<Column>1</Column>
<Column>2</Column>
<Column>3</Column>
</Row>
<Row>
<Column>4</Column>
<Column>5</Column>
<Column>6</Column>
</Row>
</Rows>
Part - 2
The real sceanrio is that we have an inbound file that is an Excel formatted XML file full of a lot of bloated elements and attributes. The heart of the data is a set of rows with columns similiar to the Part -1 layout. But getting to just those elements seems to be quite ‘nasty’ and then I am faced with the ‘Part - 1’ situation.
Interested to hear on different appraoches.
thanks
Is there any way to identify column names in that XML? For instance additional attributes or anything?
If you take a look at an Excel Workbook saved as an Excel 2003 .XML file you can see what I am up against. Here is a sample I created using the same sample as my vanilla .XML file
Excel.zip (982 Bytes)
As a feature request that I will do later. A suggestion may be that in the EM front end - when an XML file is detected there is a checkbox to ask if the first set of elements (may be identified as an XPATH) are the column headings and then another XPATH identifies the DATA. Would that work for basic XML file structures?
Here is what I've got. The project obtains the number of columns from Excel.xml, calculates numbers of rows and columns, and pivots the table. Since the number of columns is not hardcoded it should work for any number of columns.
xml_pivot.morph (3.7 KB)
Excel.zip (982 Bytes)
This makes sense. Probably it's worth creating a special XML import mode for matrix tables. Something to think about. But so far regular pivoting works. Calculating row and column numbers isn't convenient without special functions for obtaining remainder and division -- we will add these.
Thanks Dmitry, I will take a look now.
Took a look. Very impressive. Thanks heaps. I will now see if I can take the Partner Inbound file they produced with Excel XML format and see if I can use your pattern. Cheers
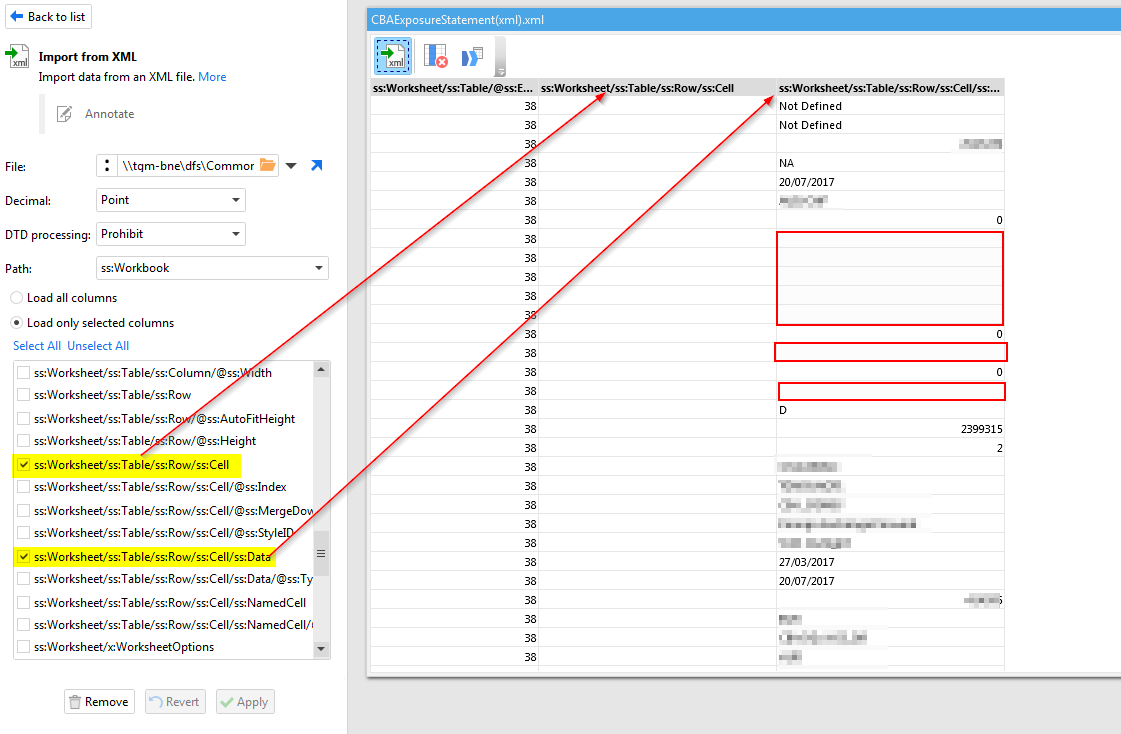
Thanks Microsoft!. I took your sample and reworked to fit the supplied XML file which appears to be an Excel 2003(XML) formatted workbook. Whilst the XML is not MALFORMED it drops DATA elements that have no data as you will see by the attached screenshot. This means that whilst there are ‘n’ columns - not all of them have data and as such they do not generate a CELL DATA Element.
So, I solved this by including the Parent element that would typically include the Child element. But when there is no source data then Excel will not generate a Element. But by including he parent element I get a place holder as if there was a element as per the screen shot.
Thanks again Dmitry. I have learnt a lot.