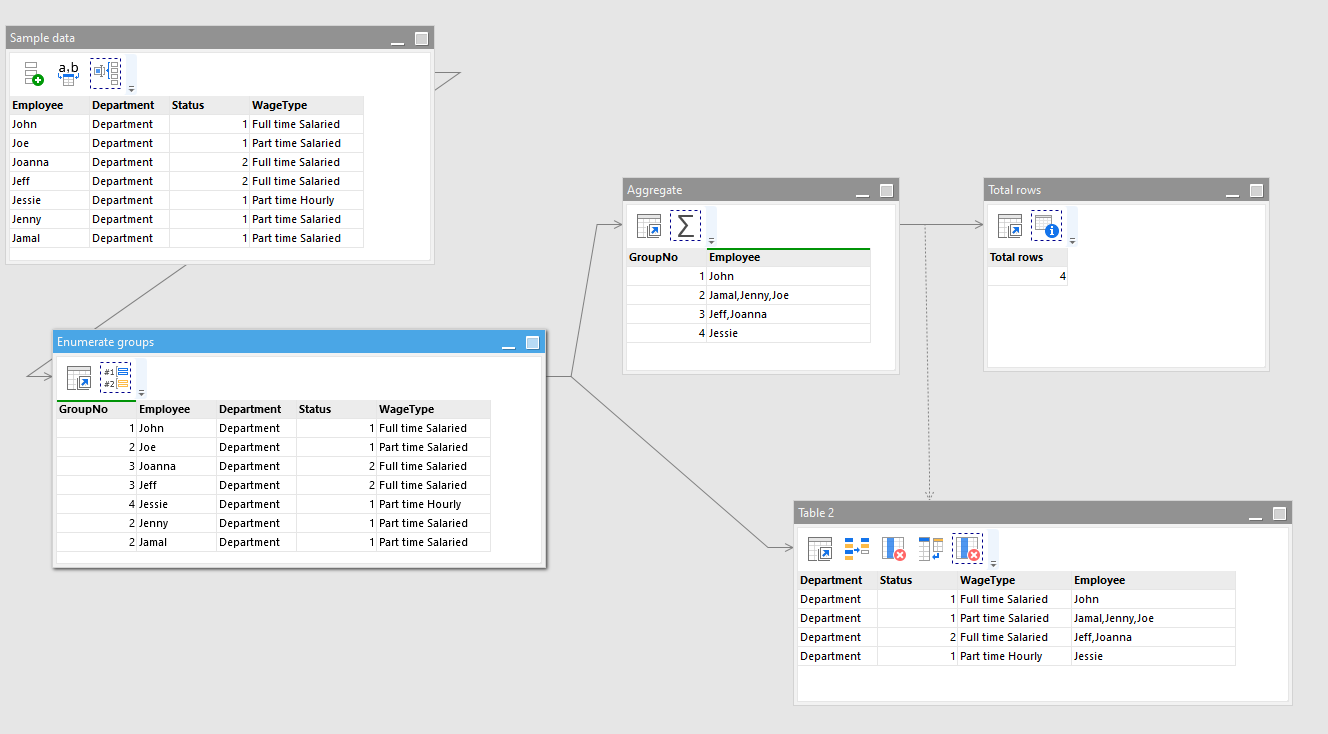
I have some employee data in a csv file (approx 170,000 rows and 60 columns wide) and I need to “condense” the data to summarize the unique rows.
Very simple example:
Employee Department Status WageType
John Department 1 Full time Salaried
Joe Department 1 Part time Salaried
Joanna Department 2 Full time Salaried
Jeff Department 2 Full time Salaried
Jessie Department 1 Part time Hourly
Jenny Department 1 Part time Salaried
Jamal Department 1 Part time Salaried
Ideally, I’d like something like this, with the actual employees grouped together where all the selected attributes match, with the list of employee names comma or pipe-separated in one column (plus a count of the unique rows)
Department Status WageType Employees
Department 1 Full time Salaried John
Department 1 Part time Salaried Jamal, Jenny, Joe
Department 1 Part time Hourly Jessie
Department 2 Full time Salaried Jeff, Joanna
Count of rows: 4
Alternatively, if this is significantly easier, a count of the number of employees with matching selected attributes would work (preferably this count would allow a drill down to the actual employee names like a pivot table)
Department Status WageType Count of Employees
Department 1 Full time Salaried 1
Department 1 Part time Salaried 3
Department 1 Part time Hourly 1
Department 2 Full time Salaried 2
Count of rows: 4
For context, there are about 50 different attributes to be checked.
What would be the best technique for this, bearing in mind the (large?) number of different attributes to be checked? Neither the group or aggregate transformation steps appear practical.
This isn’t ‘live’ data, it isn’t particularly volatile and this is a ‘one-off’ exercise I need to do so ultimate efficiency is not a requirement…
Thanks in advance