We're experimenting with additional in-memory data compression. The first test results look promising. On average, we see RAM footprint reduced by a factor of 3 at the cost of slowing down calculations by only 10-15%. And we're not done with optimizations yet.
If things go well, we will be adding an option for enabling super-compression in v4.2.1.
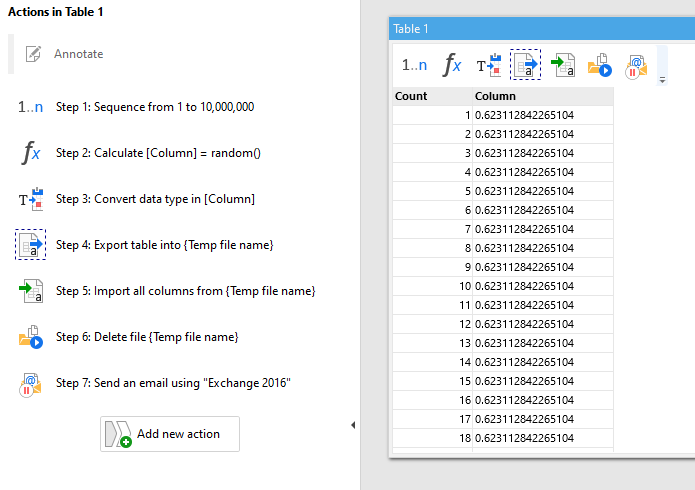
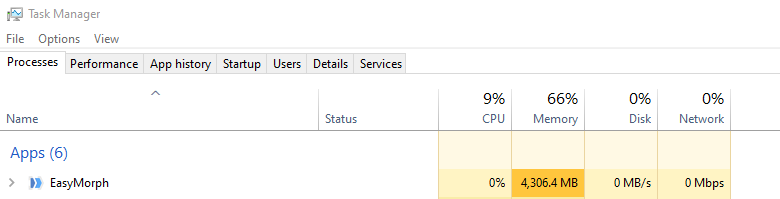
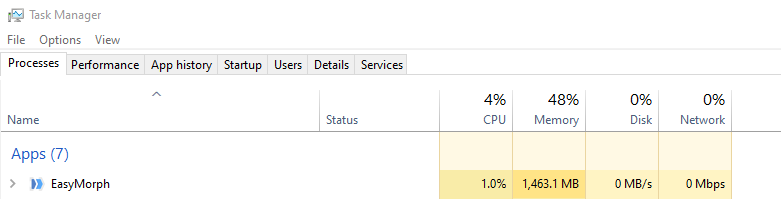
Here is an example of the super-compression in action. The chart shows RAM consumption with and without the super-compression when loading a relatively large CSV file (445K rows, 84 columns). The total load time hasn't changed.
The bigger datasets, the better the gains from super-compression
In projects with relatively small datasets and lots of actions the super-compression has a moderate effect
Super-compression is generally stable but we want to keep it in experimental mode for couple releases, just in case. In v4.2.2 it will be turned ON by default in Launcher, and by default OFF in Desktop and Server.
Super-compression has basically no performance overhead. In I/O heavy workflows (as in the test above) it even improves performance.
We're intended to make super-compression always on after a couple releases. However, the final decision will be made after examining field reports.
Does this also mean that if we have a large dataset, that compression is directly done as records are imported so that we do not need a lot of RAM to temporarily store the data in memory before super compression occurs ?
Yes, the compression on import is applied on the fly, while data is being imported into EasyMorph. It's not buffered in RAM first.
If you can, please measure memory consumption for the same file import before v4.3 and in v4.3, and post here. It would be interesting to see the difference. Remember to turn super-compression on (in menu About) in Desktop, because by default it's off.
When we switch on super compression in EM desktop, does this also have an effect when data is imported from a database ? Or does it only has a significant effect when data come from files ?
When we have already the data imported and we switch super compression on after import, does it compress the data also or do we have to put it on before import ?
Is super compression already stable or still experimental ?
Super-compression affects absolutely all actions in EasyMorph, not just import, and not just import from files.
If you turn super-compression on when some actions have already been calculated, this won't make them recalculate so super-compression won't be retroactively enforced on them. It will only work for newly calculated actions.
It's very stable so far. We haven't received any bug reports on it. Super-compression will be on by default in all EasyMorph products (Desktop, Launcher, Server) starting from v4.4, and will become permanent (i.e. the switch will be removed) starting from v4.5.