Both exception handling and workflow branching are possible through [not so elegant] workarounds. Workflow branching will get "normal" implementation in version 3.7 (it's actually the headline feature of v3.7) through the ability to conditionally derive tables. If the condition fails then all transformations in the derived table are skipped.
Until then here are the workarounds:
Workflow branching
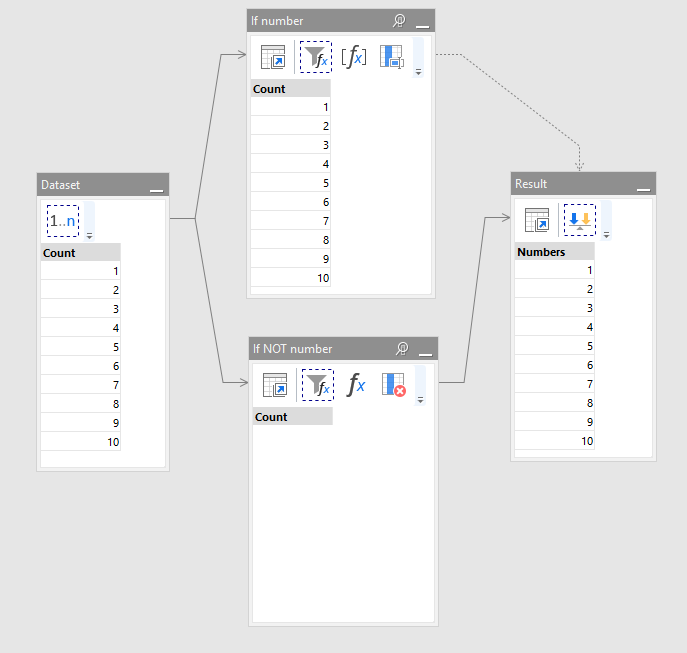
In a simple case, when only calculation is necessary, workflow branching can be done by simply having two derived tables that start with "Filter by condition" transformations each. The conditions should be opposite (i.e. mutually exclusive). E.g. one filter is X >= 0, and the other one is X < 0. This would make either one, or the other table empty at a time, but not simultaneously. The branches are merged back into one table using the "Either" transformation.
See this example for simple branching:
if_then.morph (3.6 KB)
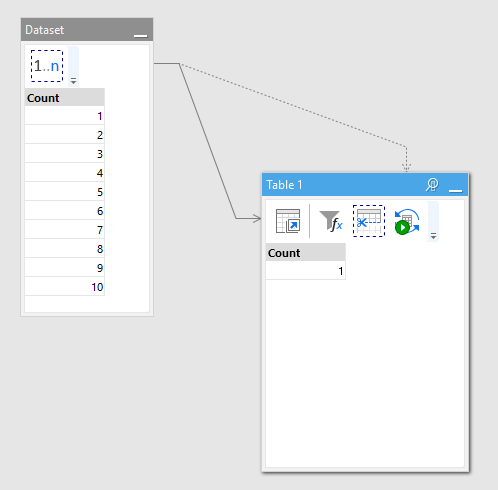
However when it's necessary to run a side effect transformation (e.g. export file, run program, or execute DB statement), then the approach is a bit more complex, and requires a workaround. After filters insert the "Keep" transformation to keep top 1 row. If the derived table is empty, then the "Keep" transformation won't change anything. If it's not empty, then it will have only 1 row. Then use "Iterate" or "Iterate program" to call subproject or run a command. Because Filter + Keep will make either 0 or 1 row, there will be either no iterations at all, or 1 iteration. Not very elegant, but works.
See this example:
if_then_with_helper.morph (2.3 KB)
helper.morph (1.1 KB)
In a similar fashion it is possible to implement SWITCH...CASE kind of logic -- just make a separate derived table + filter for each case.
Also check out this blog post: http://blog.easymorph.com/2015/08/conditional-workflow-in-easymorph.html
In version 3.7 this workaround won't be necessary.
Exception handling
An error, or "Halt" transformation would stop project execution. The only way to handle project errors without stopping is to run the project from another project using the "Run program" transformation (instead of "Call") that, for instance, executes morph.exe /c can_fail.morph in the command line. The "Run program" transformation can capture console outputs -- both STDIN, and STDERR. By analyzing if STDERR output is empty or not, it is possible to detect if can_fail.morph failed or not, without stopping the project. Again, not so elegant, but can do the trick.
PS. As for implementing a "normal" way of handling exceptions, the ideas are floating around a monadic-style solution (in terms borrowed from functional programming). It could be a special kind of derived table (exception catcher) in which transformations are executed only when calculation in the source table fails. This would allow having different recovery logic in different points of transformation logic. But it hasn't been finalized yet and no roadmap for it available as of now.