Version 4 of EasyMorph will deliver many exciting changes to EasyMorph. Here I'm going to explain a few major features coming in v4 and would like to hear your opinion on them. This is to make sure that we don't miss anything important and maybe hear some new bright ideas from the EasyMorph user community.
Here is what ver.4 is going to look like (conceptual drawing, actual look may be different, click to zoom):
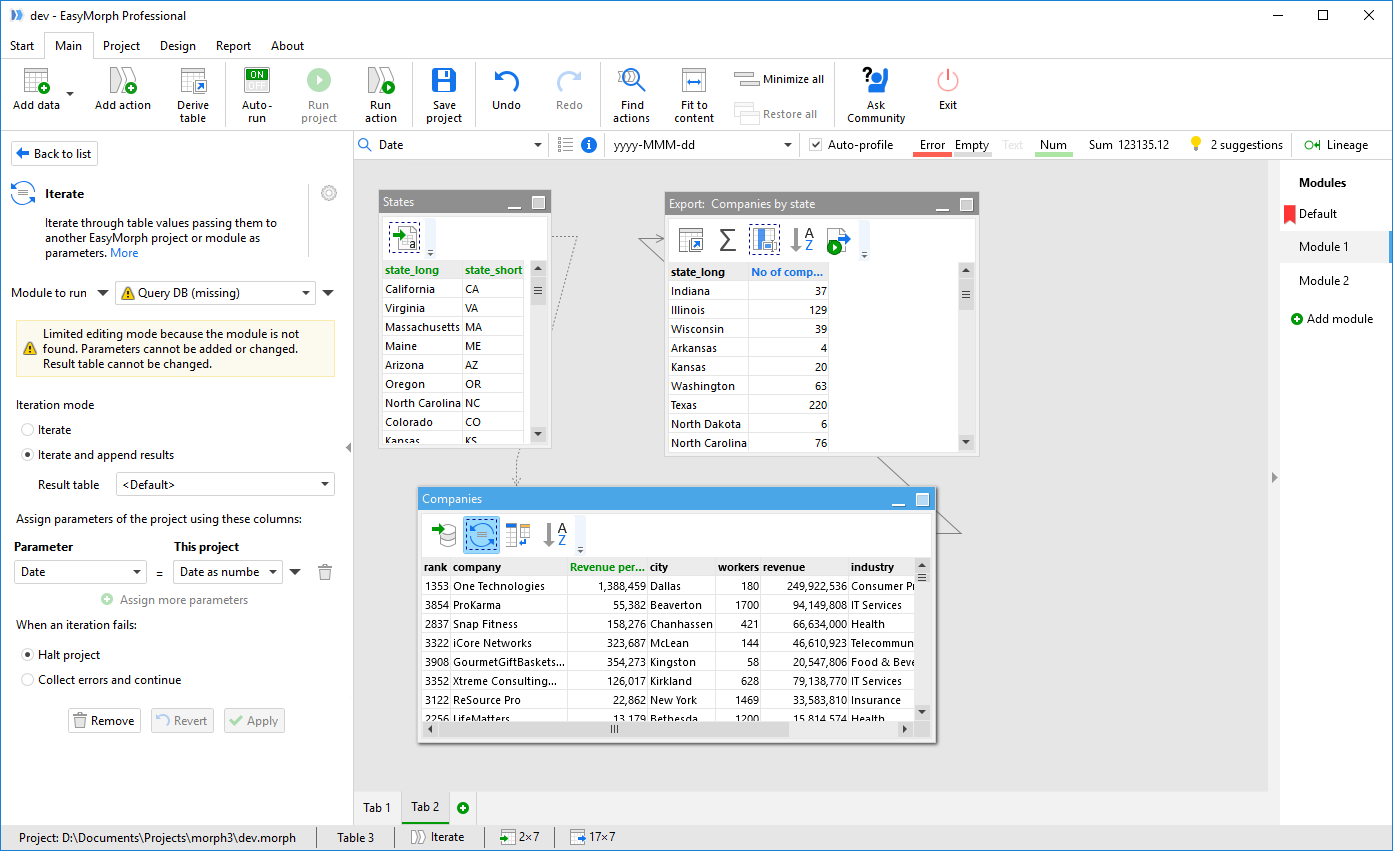
As you can see there is a lot of changes here. Let's go through the most important ones:
Modules
Modules (previously known as blocks) eliminate the need to have a separate project for iterations. The ability to iterate an external project will remain, but it won't be strictly necessary anymore. In the vast majority of cases iterations will be arranged using modules.
A module is very much what you used to think of a project previously -- it has tabs with tables and charts, actions in tables, parameters, and optionally marked default result table. The only difference between a module and the old understanding of a project is that modules don't have embedded connectors.
A project will consist of one or more modules. Embedded connectors are stored in project (as it is currently) and are available to all modules in the project, as well as shared connectors. You can switch between modules using the new right sidebar (can be seen in the screenshot above). The sidebar is collapsible. It can be hidden when not necessary. Switching between modules can also be done by hot keys Ctrl+PgUp, Ctrl+PgDown.

All actions that previously required an external project -- Call, Iterate, Iterate table will be able to use modules too (you can see it in the left sidebar in screenshot above). Using a module will be the default choice in them. It will also be possible to specify a module name using a parameter.
Therefore, instead of one project iterating/calling another project, one module will iterate/call another module in the same project. Any module can call/iterate any module in the same project as long as it doesn't create a cyclical dependency.
Modules are independent from each other. It's not possible to reference a table in another module in an action. E.g. merging or appending a table from another module won't be possible. However, as with projects now, it's always possible to pass a dataset from one module to another module either in-memory via the Input action, or through an external file (e.g. .dset).
In a project there always is a default module. It's marked with a red flag, just like default result tables. When a project is executed by a Server/Launcher task, or another project, the default module is the starting point.
Modules can be cloned, or copied/pasted to other projects.
Modules bring in many advantages:
- No need to create another project(s) for iterations
- No need to save iterated project to apply changes
- Publishing to Server is simplified because modules eliminate the need to publish related sub-projects
- Easier designing/debugging
- Elements of prod/dev version control -- instead of duplicating a project file, clone its module make changes, then mark as the default module and publish. If something doesn't work right, you can rollback the changes by setting the original module as the default one. Basically, you can have multiple versions of a workflow in one project in different modules.
- Easier project sharing as even complex workflows can be wrapped into just one project and shared
Column bar
Another big novelty in v4 is the addition of the column bar (can be seen in the screenshot above). The column bar is used for finding columns, changing column format and displaying various metadata about currently selected column.
![]()
The column bar will make editing actions more convenient. Currently, when editing an action if the user clicks a column it forces switching from the action properties editor (in the left sidebar) to column format settings. This is inconvenient, because it's frequently necessary to explore a column while editing an action. However, since both column and action properties are currently shown in the same sidebar, it's not possible to show them at the same time and requires switching back and forth.
The column bar solves this problem and removes the inconvenience. With it it will be possible to edit action settings and search, explore columns and their values at the same time.
Another convenience is the instant indication of column data types, so that you can click a column and immediately see if it contains numbers, text, errors or empty values. Clicking a data type indicator will instantly filter column values to that particular type (by adding the "Filter by type" action). The sum of column values will be shown as well.
It will be possible to change formatting of multiple columns at once, as it is currently.
Finally, the column bar will show automatic suggestions. The suggestions will automatically detect common data quality issues such as trailing spaces, or text values that are actually numbers.
Lineage
EasyMorph will track and display column lineage. Lineage is information about the column's lifecycle -- in which action it was created, in which actions it was modified, how it changed from action to action.
Notice in the screenshot above that some columns have green or blue headers instead of black ones. A green header indicates a newly created column. For instance, all import actions basically create new columns and therefore their resulting datasets will always have green headers.
A blue header indicates a changed column. For instance, columns changed using the "Modify column" action will have blue headers. Merged columns in the "Merge" action will also be shown blue (they are not new because they were created in another table). Renaming a column modifies it, therefore a renamed column will also be shown blue.
It will be possible to see the full lineage chain for each column -- starting from the action that created it and all the actions that modified it.
Lineage also changes how column widths and formats are managed. Changing column format/width will automatically change the format/width of this column in results of all actions along the lineage path. This should simplify column formatting and make it more intuitive.
Finally, column lineage opens the possibility to instantly see column metadata -- e.g. the data origin (e.g. database table name, file name), the original name in the external system, annotations with explanations of encoded column values (e.g. 0 = male, 1 = female). It also makes it technically possible to automatically populate column metadata from external systems when importing it into EasyMorph.
How does all of it sound to you? Comments, suggestions, questions are welcome.
PS. Version 4 is planned for release in June this year.