Hi
I can see me being in a hurry writing the original post, made interpretation almost impossible 
I actually think I managed to get something working, but was asking to see if there was an easier way to do it.
In the example below, I have a project with 2 modules; 1 for importing and processing Item Manifest telegrams, 1 for importing and processing Carton Manifest telegrams.
Source of data is an example log file containing first 300 rows of data of a real log file.
The telegram build is as described below.
1, A and B all relates to the Item Manifests;
A = the string to decipher - documentation underneath
B = example of string
2, C, D and E all relates to the Carton Manifests;
C = the string to decipher - documentation underneath
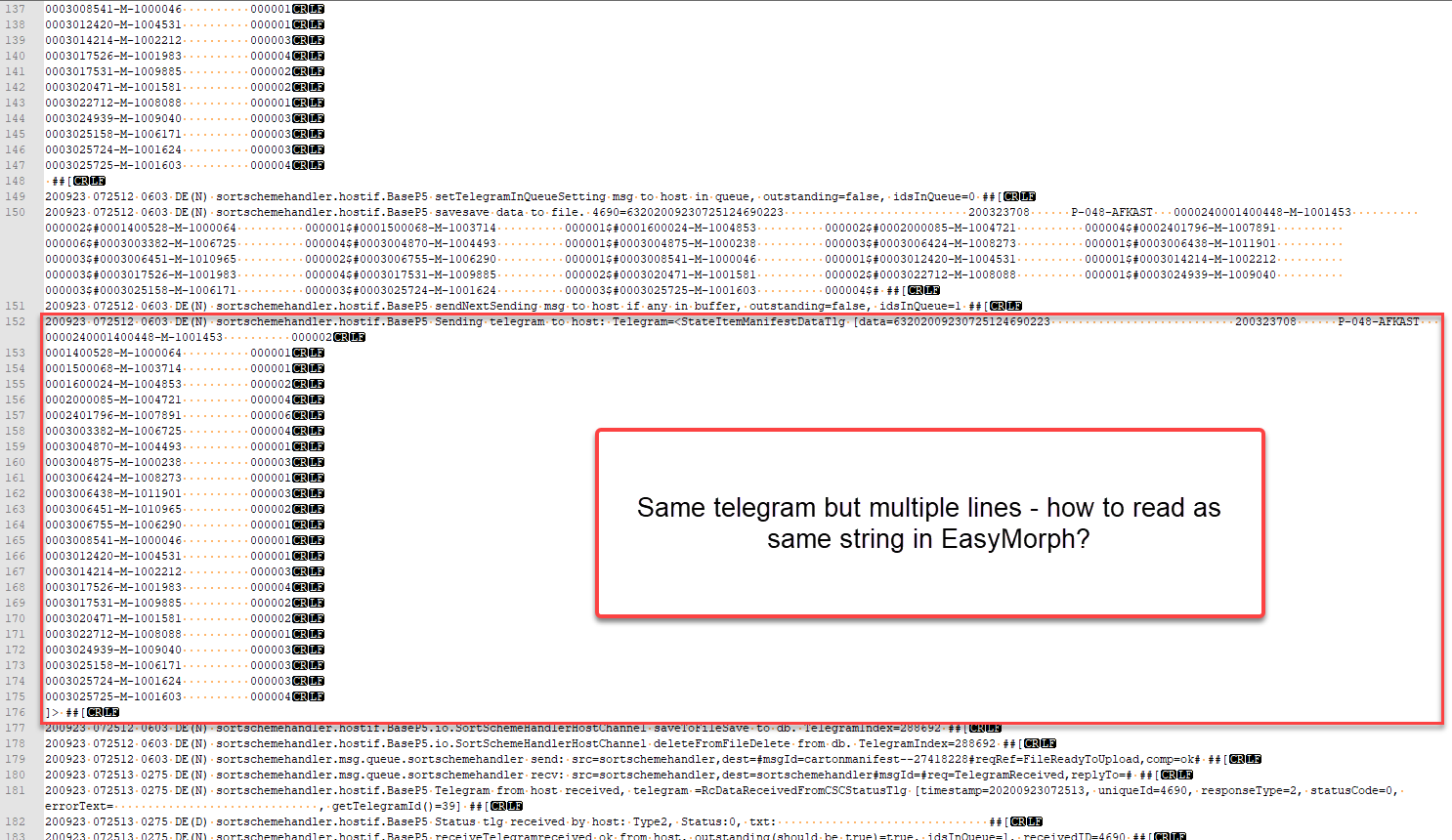
D = comment regarding the issue - items in carton are put in separate lines within the telegram, but on new line with no link, when reading in EasyMorph or NotePad++
E = example of string - only for first item, so the issue is not presented in the example
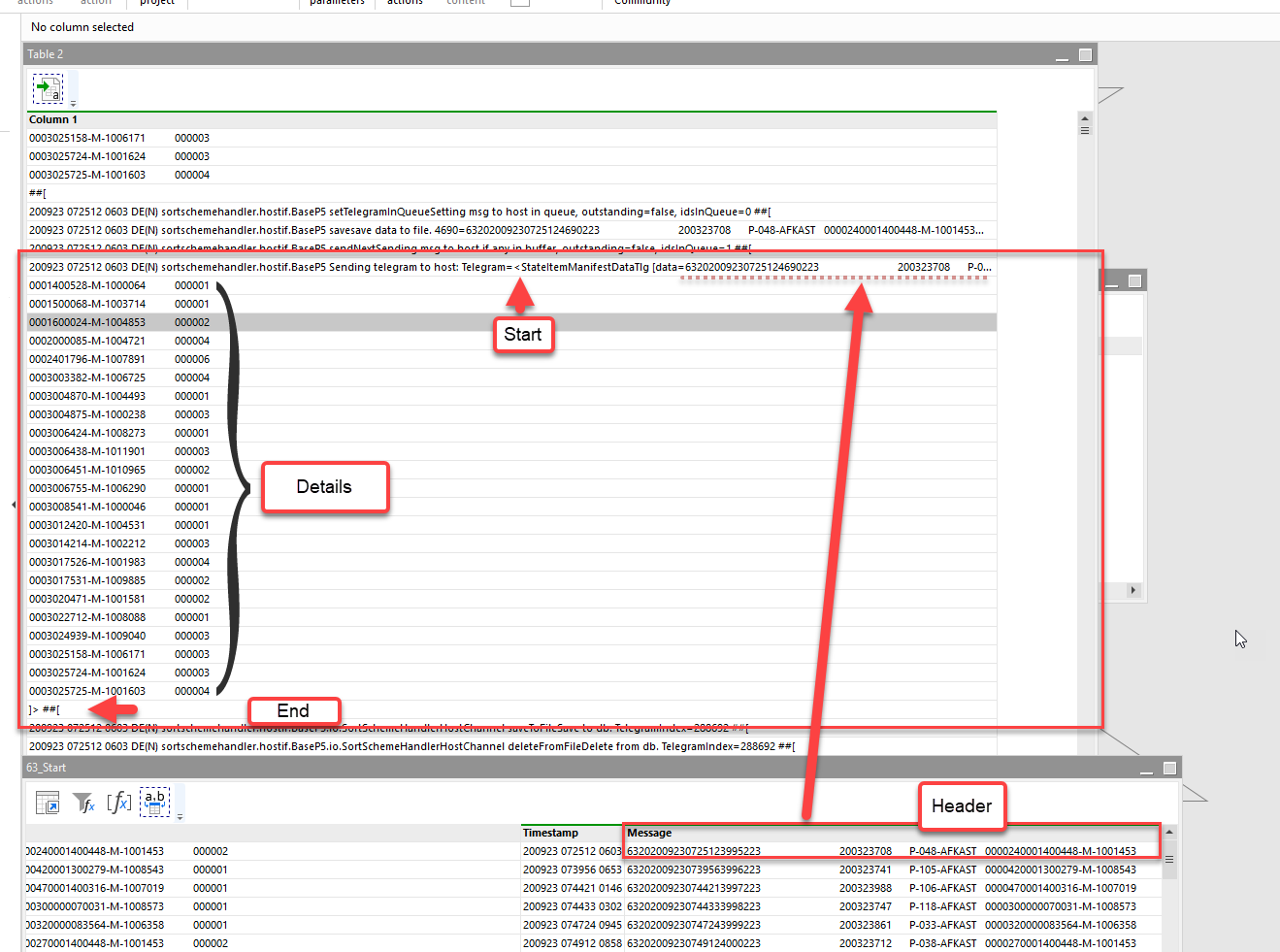
When reading the log file in Notepad++, it is obvious what to see the issue;
So, in my own solution, I read the file, and based on some logic in import column (Column 1) I defined a type for the relevant lines;
Type = if
contains([Column 1],'text:63') then 'Start' else if
(len([Column 1])=36 and left([Column 1],2)='00') then 'Data' else if
[Column 1]="##[" then 'end' else ''
Then I defined start of the string among the endless number of lines;
Start = if [Type]='Start' then replace([Column 1],
' DE(D) sortschemehandler.hostif.BaseP5 Sending status telegram to the host (or putting in buffer): text:','|')
Then I split the column 'Start' to get a time stamp and the message.
Then parsed the message using telegram documentation from excerpt above.
Made 2 new calculated columns from the extra lines within the telegram- SKU ID and Number of items sorted.
Calculated an end of the telegram based on the type defined in first step.
Fill Down from telegram header to 'end' to get header details on SKU ID / Detail level.
Count records in header.
Filter for only relevant telegram types.
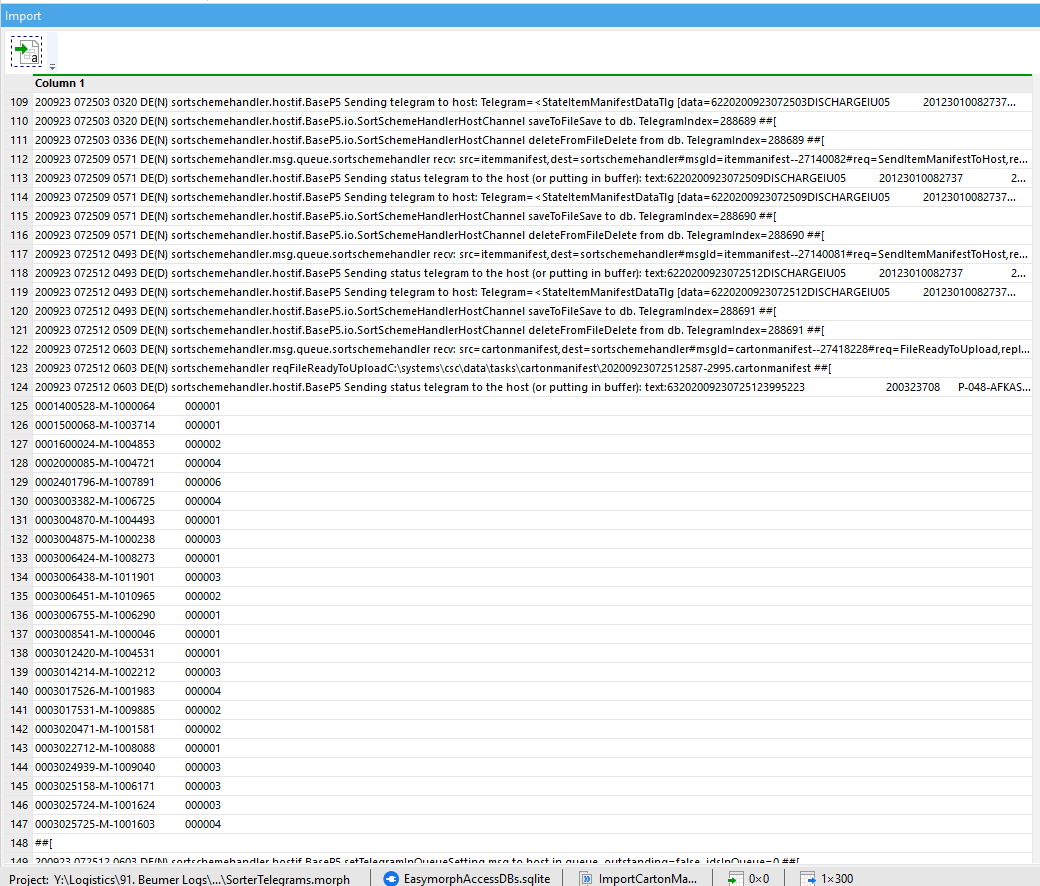
Starting point being the log file shown above, or in EasyMorph:
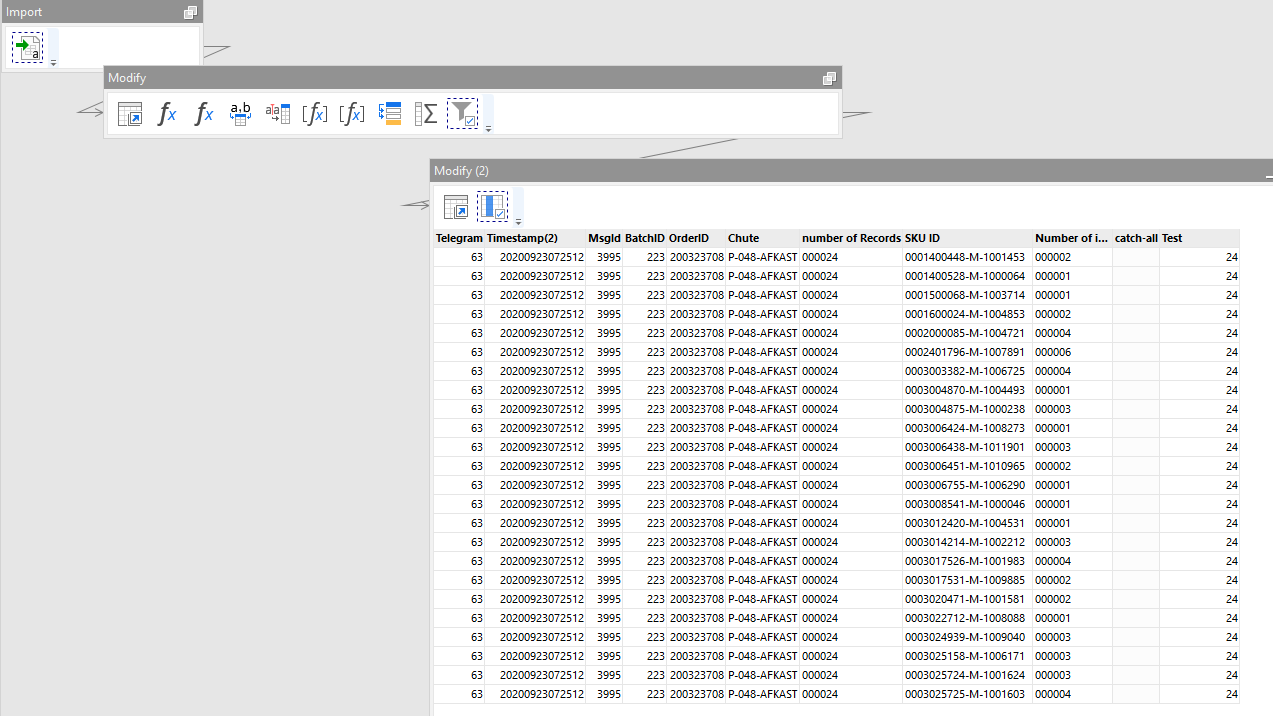
Current end point being a clean table with detail and header information:
Spoiler alert - I was originally looking for a shortcut to the 9 steps in table 'Modify' 
Example.zip (6.8 KB)