I import these CSVs and apply a number of actions to produce a dataset (I call it Pre-Processed) that I want the iterations derived from.
It seems if I have everything in one project file, the iteration runs everything from the beginning and each iteration takes 2 minutes with about 1 minute 55 seconds being the initial Pre-Processed sctions.
However, if I export the Pre-Processed dataset as a CSV and then run a new project where I just iterate off that I can process over 600 iterations in 5 minutes!
Is there a way to specify where an iteration should start from, e.g. a table or module so that it doesn't start from scratch each time so I don't have to create an interim Pre-Processed file every time?
I've looked at
but it seems that the solution I'm using is currently the way to do it?
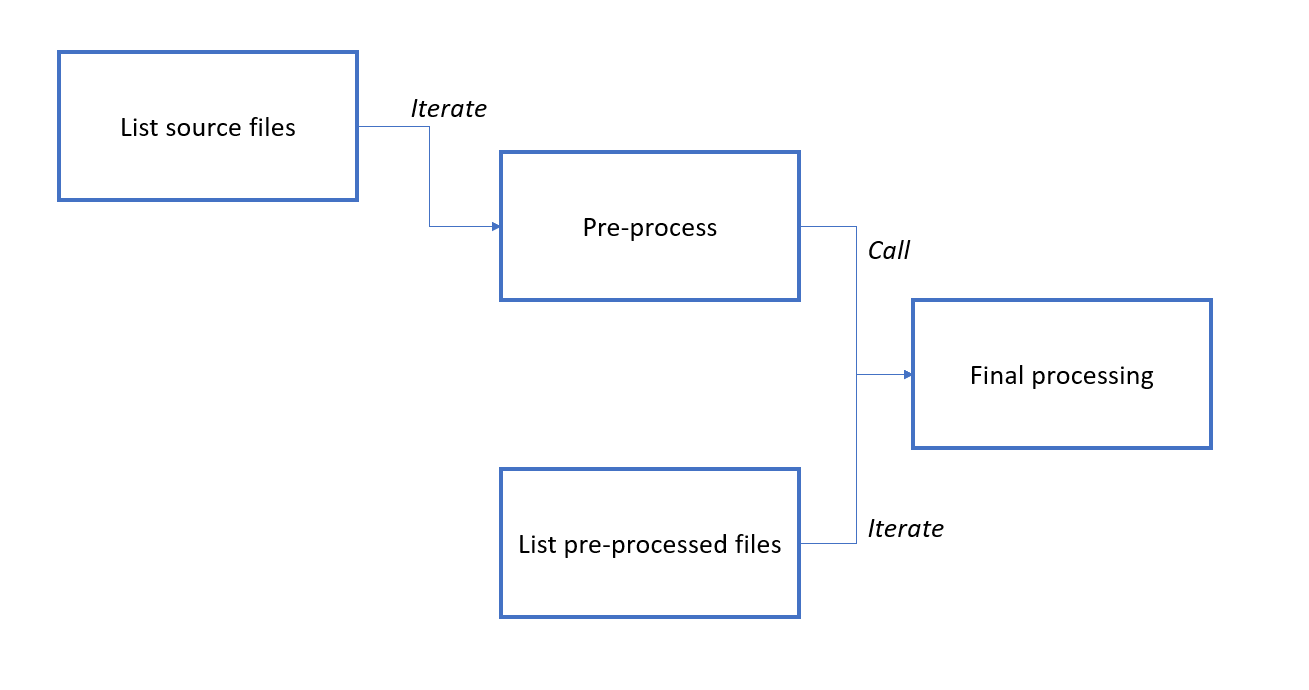
You don’t have to use a new project. Just create a module in the existing project and start from that module. For instance, your project can have the following module structure:
By the way, you can use the “Export dataset” action to store pre-processed files as EasyMorph datasets (.dset) instead of CSV files. EasyMorph reads and writes .dset files up to 100 times faster than CSV. It will make processing pre-processed datasets even faster.
I don’t think I’ve explained this properly or I’m missing something - I did try breaking it out into modules but it keeps re-processing everything.
I’m creating a solution that works (and I see what you mean about the .dset!) and will re-visit this once I’ve finalized everything - still have some additional data to add and process which I wasn’t notified about!!!
FYI at the moment although I’ve got a 2 step (EasyMorph Project File) solution, I’m able to process and create the client reports in under 5 minutes as opposed to 36 hours, so even as is it’s a massive win!