A general question on the way iterate and append works and why it drops the previous columns
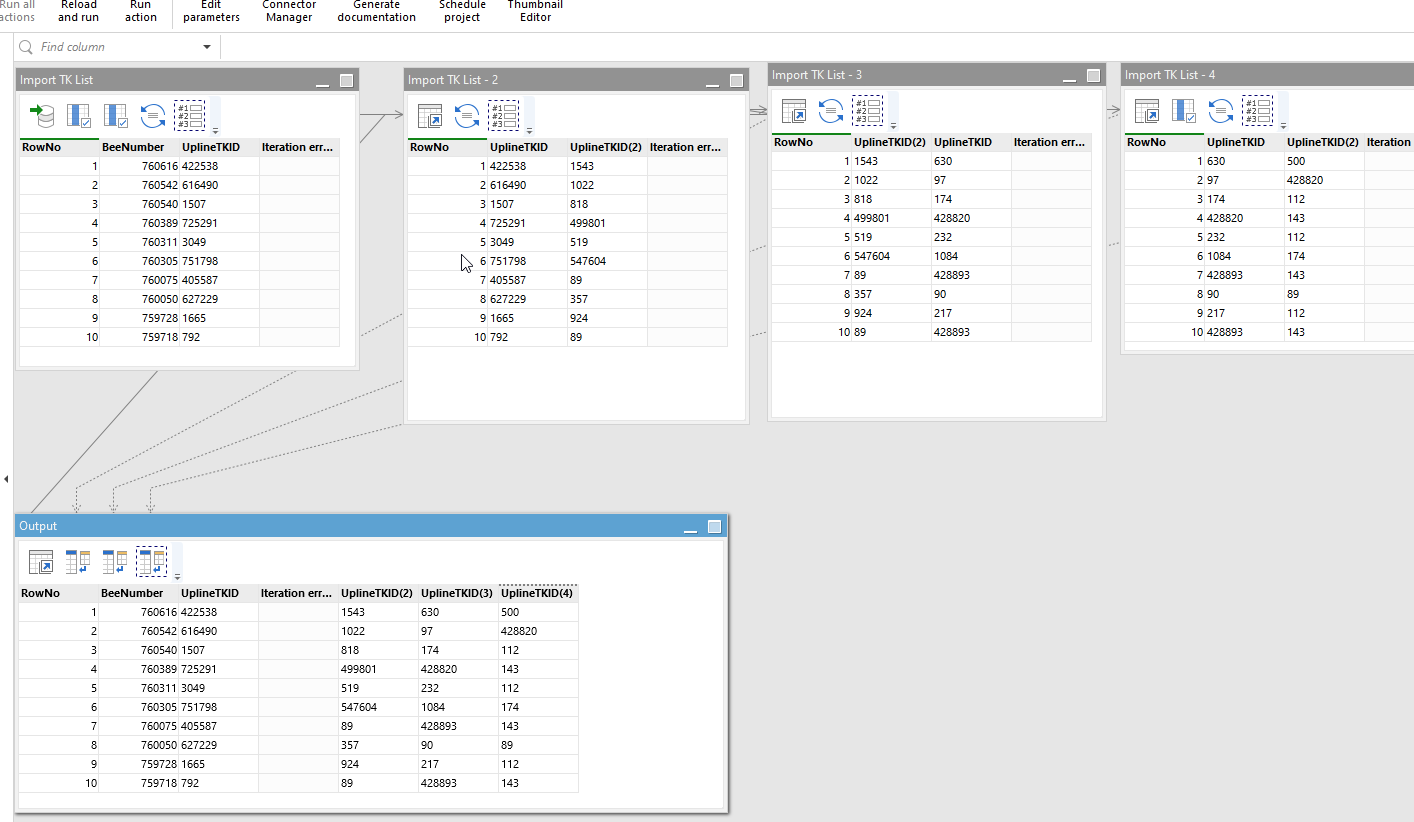
Lets assume a data set has 1 column as seen below
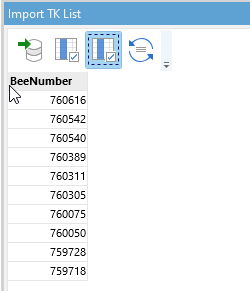
If I iterate and append to look up another column I will add to this as seen below
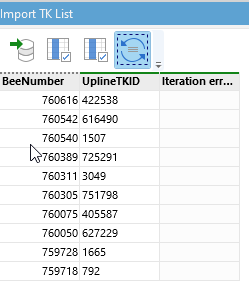
However, if I add another append it drops the previous columns, as seen here
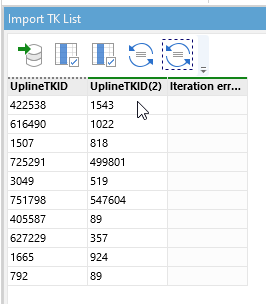
The only way I can think to get around this is to keep deriving it and stitching things back together by using row number which is something like this:
Is there a better way to handle this type of scenario?
Iterate & Append doesn’t keep any columns - all columns of the input dataset are replaced with the result dataset. It’s just the result dataset automatically creates columns with parameter values used for iterations and appends them to the columns returned from iterations.
There can be several ways to deal with your case:
-
Merge as you did. Only instead of enumerating and merging, you can just use the “Append” action in the “Append columns to the right” mode because all datasets have the same number of rows in the same order.
-
Append at the bottom and then Pivot
-
Don’t create derived tables, but instead use two-level nested iterations. The upper iteration level for 4 iterations (probably using “Iterate table”) and the inner for 10 iterations, so the result is 40 rows) and then Pivot.