Good morning,
I’m trying easymorph free version with the target to buy the professional version.
After finished my first project, I have many questions about use and the futures of the software.
1 - Sandbox
How can I do the data sandbox refresh automatically?
I have a table with a filter that I use to put data to a sandbox, but when I change the filter, the refresh of data sandbox don’t run.
Only with manual “Send to Sandbox” allows the data refresh.
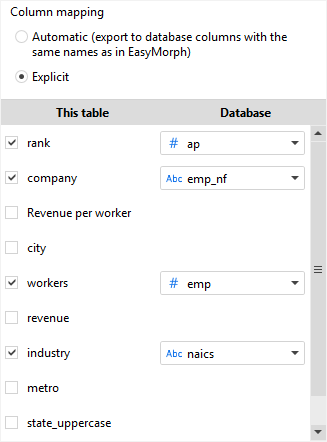
2 - Mapping Fields
I’m trying to export data from my sandbox to an external database table.
This is the situation:
My sandbox has 10 columns (item, colour, supplier, customer, etc…)
External Tables about 40 columns.
For to export the sandbox to external tables, I had to add every columns of destination tables with
the transformation “Calculate new columns”, because the transformation “Export to database” allows only table select
and the mapping columns is not expected.
There is a better way to do it?
There is, for example, a personalized object that allows the choice of the table columns where to put the data to export?
3 - Mail
Is possible to send email for detection the procedure fault?
4 - Main procedure/Sub procedure
Is possible to create a main procedure that calls two or more sub procedures?
I would like that every sub procedures start up only if the result of previous sub procedure be successful.
Thank you for any replies
Regards