Incremental loading of data is a term which refers to extracting and processing only data which is new or has changed. Doing this is a “no-brainer” as my American friends would say. Why waste all that time and processing power redoing what we’ve already done. So if it’s a simple matter of common sense, why don’t all ETL and data preparation pipelines incrementally load data?
The simple answer is that in the real world it's a lot harder to implement than you might at first imagine!
Firstly, there isn’t just a “one size fits all” solution. There are a lot of factors to consider:
- There are an almost infinite number of different database systems, APIs, etc to cater for.
- Some systems only allow records to be added but never updated or deleted. Whereas others allow records to be modified and/or removed as needed.
- How can we identify what has been added, changed or deleted?
- Just because there is a “created” or “last modified” field, is it actually accurate? Is there some undocumented process or stored procedure updating records without updating the appropriate timestamp fields.
- If records can be modified or deleted, is there a unique primary key field in the table which we can use to identify the same record in a cache of data?
- Maybe I’m only loading some fields and so only care if those fields have changed in the source.
- Can I modify the source system in some way to add timestamps or flags to allow me to identify changes if there isn’t already a way?
- What percentage of the data is expected to change each time? If it’s a low percentage then it might actually just be quicker to load all of the data than to bring slow “where” logic into the process.
- Even though data isn’t removed from the source system, do I need to remove some data each time? Such as if I only need the last 1,000 records or only data for the last 28 days.
- How often do I need to refresh the data? If the answer is once a day and I can run it over night when no one is around, maybe I don’t care how long it takes.
- Where am I going to store the data I’ve already loaded and how should I merge any new data with it.
These are just some of the questions to consider and I can’t stress enough how what seems like a simple principle can become incredibly complicated. I’ve lost count of how many times over the last 25 years I’ve worked with customers who’ve implemented incremental loads in various data and BI tools and who can’t fathom why the data in their reporting or BI system slowly diverges from the source system over time. The answer can almost always be summed up as “they’ve failed to consider all of the possibilities”.
We also need to consider that not all systems, databases and other sources of data have any way for us to identify and therefore only load what has changed. If this is the case, we might have to load all of the data from the system but then only incrementally process the records which we haven’t already. This is of course less efficient, but if the processing is complex and takes a lot of time, it may still be a worthwhile thing to implement.
With all this in mind, it should be clear that I can’t simply provide an EasyMorph workflow for you to simply download and magically implement incremental loading of data in your organisation. What I can do though is to provide you with some examples and explain how and why they work the way they do. And hopefully you will be able to use them as a rough guide to create a solution for your incremental data loading needs.
Example 1 - The good old “Last modified” date
Probably the most common sources of data we need (or want) to incrementally load from are databases. And the most common method you will come across for identifying whether or not a record has changed in a database table is for the table to have a field which contains timestamps indicating the last time each record was last modified. So let’s consider just such an example.
In this scenario, there are a few prerequisites we need to have in place:
- The database table needs to have a field holding the last modified date and time.
- We will need to be able to create “from” and “to” timestamps between which we wish to load new data each time we run. So we’ll need some way of keeping a record of the “to” timestamp so that next time we load data we can use it as the “from” timestamp (more on this in a second).
- We need somewhere to store a cache of the data as it was the last time we loaded it. We can then update this cache each time we run.
For now, let’s keep things simple and ignore complicating factors like handling deleted records or performing full reloads periodically to ensure accuracy. The simple steps we need to perform each time to incrementally load the data are as follows:
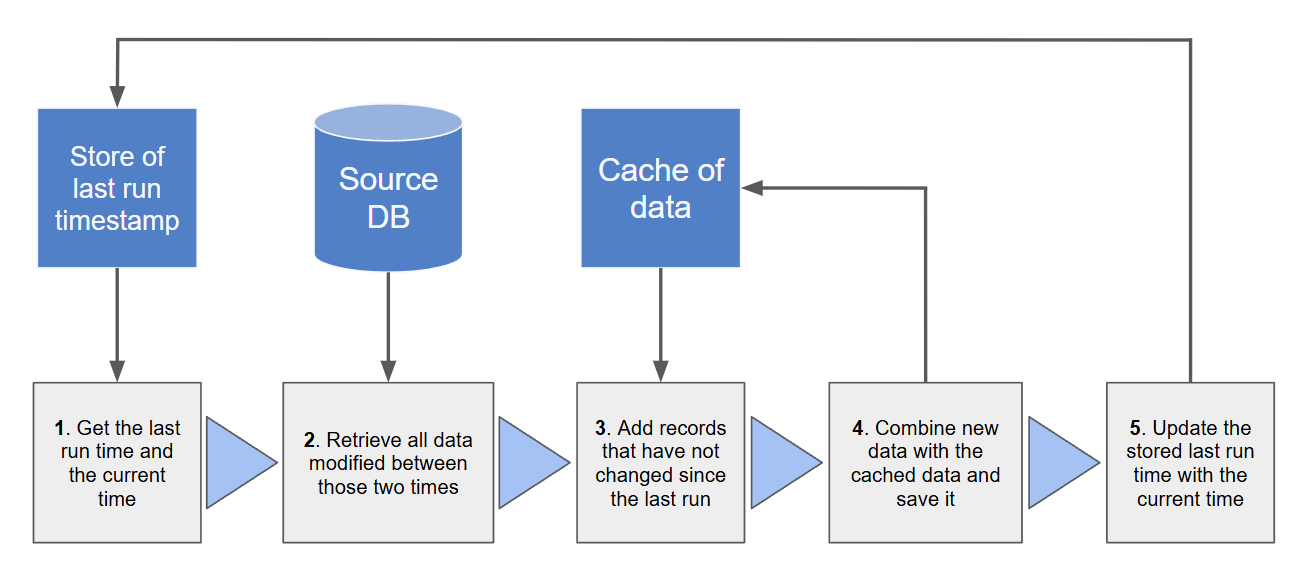
And here is an EasyMorph project which implements this process with a few extra considerations thrown in, including:
- Checking if there is an existing cache and handling what to do if there isn’t.
- Handling performing a full data reload if needed.
- Because it's an example, the ability to modify and add some records to the database so we can see the incremental loading in progress.
Incremental DB Example.zip (13.6 KB)
The zip file contains 2 files as follows:
- MyDatabase.sqlite - A simple database which includes a table of dummy data with a “LastUpdated” field we can use.
- Incremental DB Example.morph - The EasyMorph project which performs the incremental loading.
Inside the project you will see there are several modules and quite a few actions, so let’s walk through them. Note that as well as the included SQLite database, the project uses an EasyMorph Shared Memory key as the store for our last run time and an EasyMorph dataset (.dset) file as the cache of data. These could be swapped for alternatives if desired.
The “Main” module is the one that performs most of the magic. It does all of the above steps and I’ve annotated all of the actions so you can hopefully see what they are doing and why.
There are 2 “helper” modules which are called by the Main module. The “Get updated data” module simply extracts data from our database constructing an SQL where clause based on two parameters for out to and from timestamps.
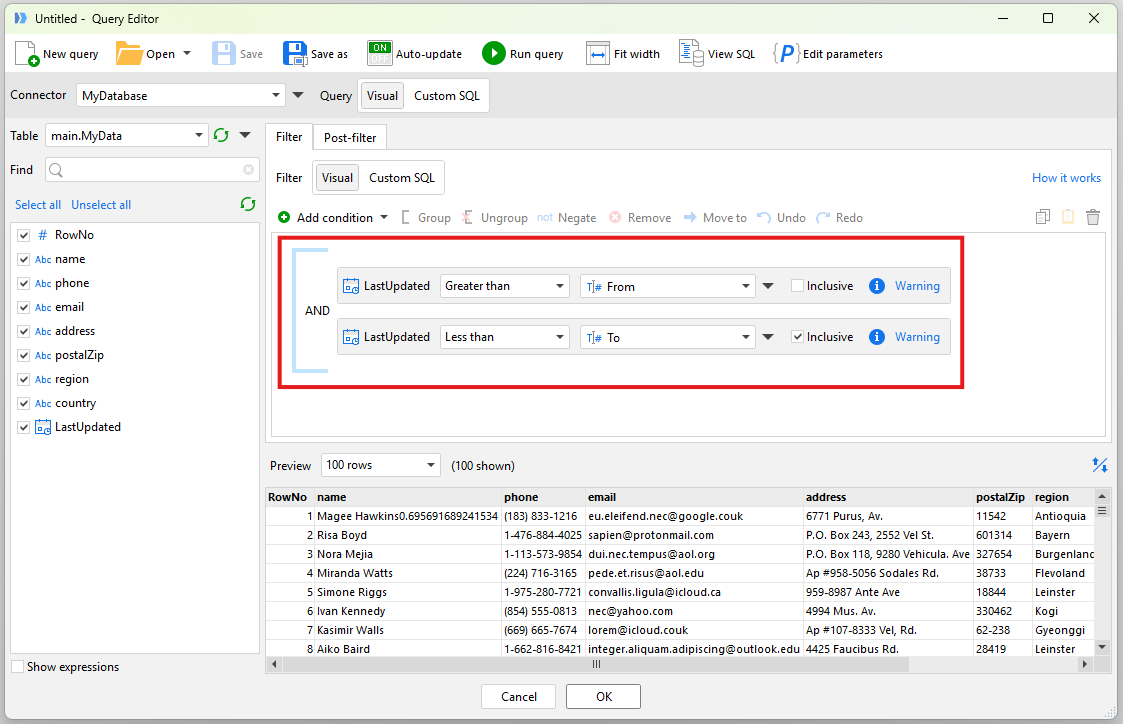
An important point to note is that the “Inclusive” options which make the SQL where clause “Greater than From and less than or equal to To”. This is so easy to miss and can be one factor in incremental data sets diverging from the source over time. If we don’t have the “or equal to” on one of the filters and a record is modified on the exact second that we use as our From or To then it will never be loaded.
The other “helper” module is the “Check if cache exists” module. It attempts to load the cache file and if none is found then it will result in an error. Being in a separate module means this error can be detected in the Main module and won’t prevent the rest of the Main module from running. You could do this by instead listing the files in a folder and checking the list to see if the cache file is listed, but would require more actions and this quick and dirty method returns the same result.
There are 2 other modules in the project. They aren’t needed to perform the incremental load but can be run manually to test this example. The “Manually set the last run time” module lets you set the last run time stored in the Shared Memory key to any value you like. Or you can even delete the key and see the effect. And because the database is a dummy one used for this example, records won’t be being added or updated. So the “Update some records” module can be run to add/or modify a record so you can see the effect when running the Main module over and over.
Note that the one thing this example doesn’t handle is detecting and removing deleted records from the cache. This is relatively simple to add as an extra step if needed by simply loading a list of all values in the primary key field (RowNo) from the database and removing any records from the cached data that don’t exist in the list.
Example 2 - The “Skip if unchanged” action
In the most recent version of EasyMorph we added a new action called “Skip if unchanged”. Like the other skip actions, it skips all other actions after it in the workflow table in which it is placed. It is different from the other skip actions in how it decides whether or not to skip.
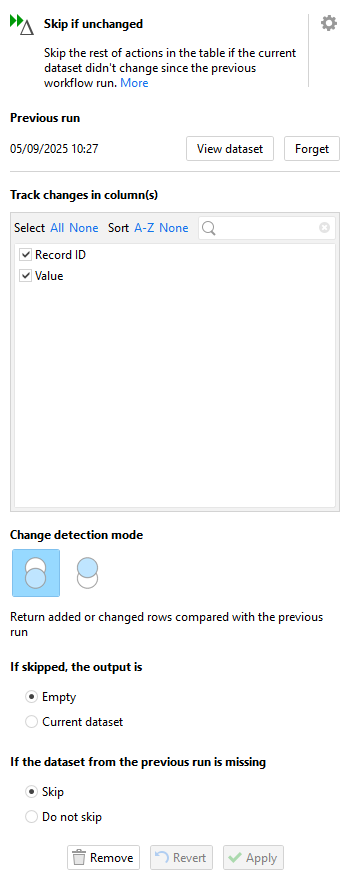
The Skip if unchanged action automatically keeps a cache of the data the first time it is run. Each subsequent execution, it checks the data against this cache and if nothing has changed then it skips the rest of the actions in the table. If data has changed then it does not skip.
The action has 2 main “Change detection modes”. The first detects if any new or modified records exist and outputs only those rows to the next action. As I’m sure you can see, this functionality is very similar to part of the process we looked at in the first example above. And so we could substitute the corresponding part for this new action.
The other mode detects if any records exist in the cached data from the previous execution but which don’t appear in the new version. This can help us handle when records have been deleted from the data source and we therefore would need to handle removing them from the data we are outputting.
Another important thing to note is the option to specify which column(s) we wish to track changes in. As we mentioned at the beginning of this post, maybe we only care if certain important columns in the data are changed.
There are also options to view the cached data and to “forget” it so that you can reset the cache should you need to.
There are other incremental loading and processing scenarios where this action's ability to easily detect if data has changed could be useful. So rather than just giving you a new version of the above example substituting in this new action, let’s instead consider a simple standalone example and leave you free to imagine the use cases for it in your data processing solutions.
Skip if unchanged.zip (2.4 KB)
This zip file also contains 2 files as follows:
- data.csv - A very simple 2 column CSV file containing a few records which we can manually change or add to and see the effect.
- Skip if unchanged.morph - The EasyMorph project which loads the CSV file and uses the Skip if unchanged action to monitor for changes.
There is only one module in this EasyMorph project which performs just a handful of steps as follows.
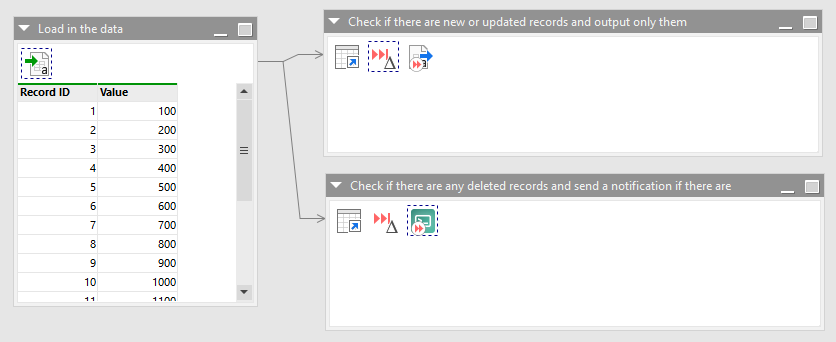
Firstly load in the example CSV file (data.csv). One branch (the top one) uses the Skip if unchanged action to detect new or updated records and if there are any, it doesn’t skip and they are output to a separate CSV file. Thinking back to the previously mentioned scenario where we need to perform complex and time consuming processing of records, we can now easily identify them and make everything much more efficient by only passing on those records to the rest of the workflow.
The other branch (the bottom one) uses the Skip if unchanged action in its other mode to identify records which have been deleted from the CSV. If it finds any it doesn’t skip and sends a notification using the “Send a message to ntfy” action. As well as alerting people to data being deleted when it shouldn’t be, we could of course use this in the previous example to detect and remove any records from the data cache when they are deleted from the source database.
If you run the project, then add, modify or delete some data in the CSV file and run it again, you can step through the actions again and see how the changes you made were identified and passed through the workflow. You’ll see that it creates some temporary cache dataset files in the same directory where the EasyMorph project is located. If you really want you can also subscribe to the “EasyMorphExample2” topic on ntfy and be notified each time you (or anyone else for that matter) runs the workflow and data is found to be deleted.
Summary
As I said at the start of this post, incremental loading and processing of data is a simple idea but which is a very complex thing to get right. But hopefully this post has given you a basic understanding of the considerations and steps involved which you can take and apply to your specific data needs. And most importantly, a look at the new actions we continue to add to EasyMorph to make complex data processing as simple as possible.