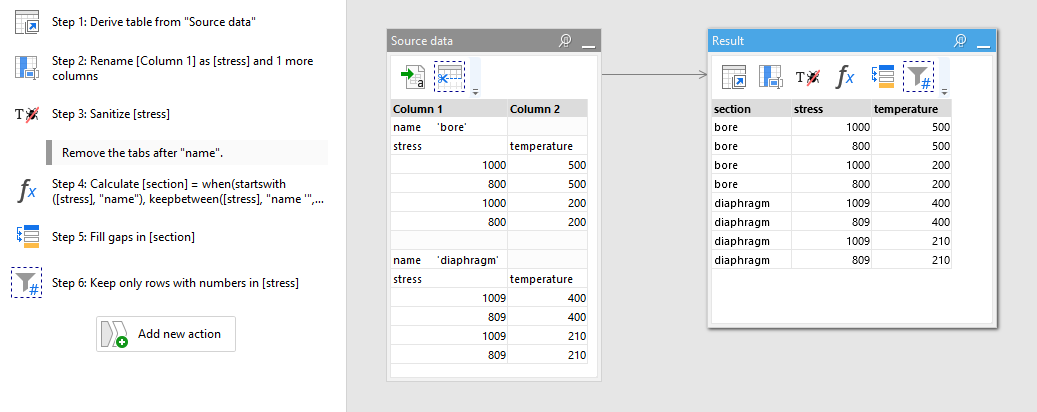
I have multiple blocks of CSV data stored in one text file. It is effectively a 3D table where each slice is written out separately. The blocks always start with a ‘name’, followed by a table of numbers. Best understood by an example:
What you have is a sectioned table. Such tables have rows that separate one section from another. Therefore, the approach is to make a column from such rows, so that indication of a section comes from a column, not a row.
Below is a sample project that does it. It works as follows:
Tidy up the source data, remove tab characters after “name”.
Create a column where all values are empty, except for the rows that indicate the start of a section. For such rows put the section name into that column.
Fill down the column with section names – populate empty cells with the section name above.
Remove rows that have no numerical data – i.e. rows with column headers and section names.