Hi EasyMorph team,
I am not sure if this has been asked before or not but,
Is there any optimization for doing ETL from 2 different databases?
because the table is very large like 150m records, importing database only takes lots time and RAM usage. is there any automated pagination/batch (by column number or index some sort) functionality in EasyMorph, if not can it be added?
Running the ETL with 10k or 100k batch working well and fast.
Regards,
Morph User
Hi,
Large datasets can be processed in chunks (partitions) using iterations which are effectively loops. Instead of loading the source dataset entirely, only a subset of data is loaded and processed at once. For instance, if the source dataset has data for 10 years, only a subset of data related to 1 month is loaded and processed at once, but this process is repeated (iterated) 120 times which is 10 years by 12 months in each year. Depending on data, datasets can also be partitioned for instance by product, region, customer, or some other entity.
From a technical perspective it works as follows:
1. Identify partitioning
Look at your source data and identify an attribute by which it can be partitioned. Make sure that one partition is not too big so that it can be processed by EasyMorph on your computer at once. For instance, if you have 150mln records in your source database but your computer has only 16GB of RAM then one partition should probably be somewhere within 1 to 5mln records.
Note that choosing too granular partitioning may lead to longer execution times because of query processing overhead in databases.
2. Create a project to process 1 partition
This project must use a parameter with the partition ID. Make sure that one partition is processed correctly given a correct partition ID.
Note that queries in EasyMorph support parameters, so you can make a query that would fetch from the source database only records with given partition ID.
3. Iterate with a master project
Create another (master) project that does 2 things:
A. Obtains a list of all partitions. Typically you can do it by querying the database for a list of distinct dates (or product IDs, customer IDs, etc.).
B. Uses the “Iterate” action to run the project created above once for each partition.
Example:
-
Your source dataset has 150mln records and is related to 15 customers. You identify that it can be partitioned by customer ID and each partition would have 10mln records.
-
Create project process-partition.morph that has parameter {Customer ID}. In that project, the source database is queried using a condition where field [Customer] equals to parameter {Customer ID}.
-
Create project iterate-partitions.morph that:
- Queries the source database and obtains a list of distinct customer IDs
- Uses the “Iterate” action to run project
process-partition.morph once for each customer ID. Parameter {Customer ID} of project process-partition.morph is assigned with customer IDs.
Let me know if you need a working example project.
Hi Dmitry,
Thanks for the detailed description. Would it be an option to build this feature into EasyMorph?
For example that users can select a partition field or batch size in the import from database action ?
This would realy simplify ETL-flows. With the append action in the export to delimited text files, we then can append the data from each batch in a CSV.
Thanks
Nikolaas
Hi Nikolaas,
You’ve worked with EasyMorph quite a lot. How would you envision it from a user interface perspective?
Hi Dmitri,
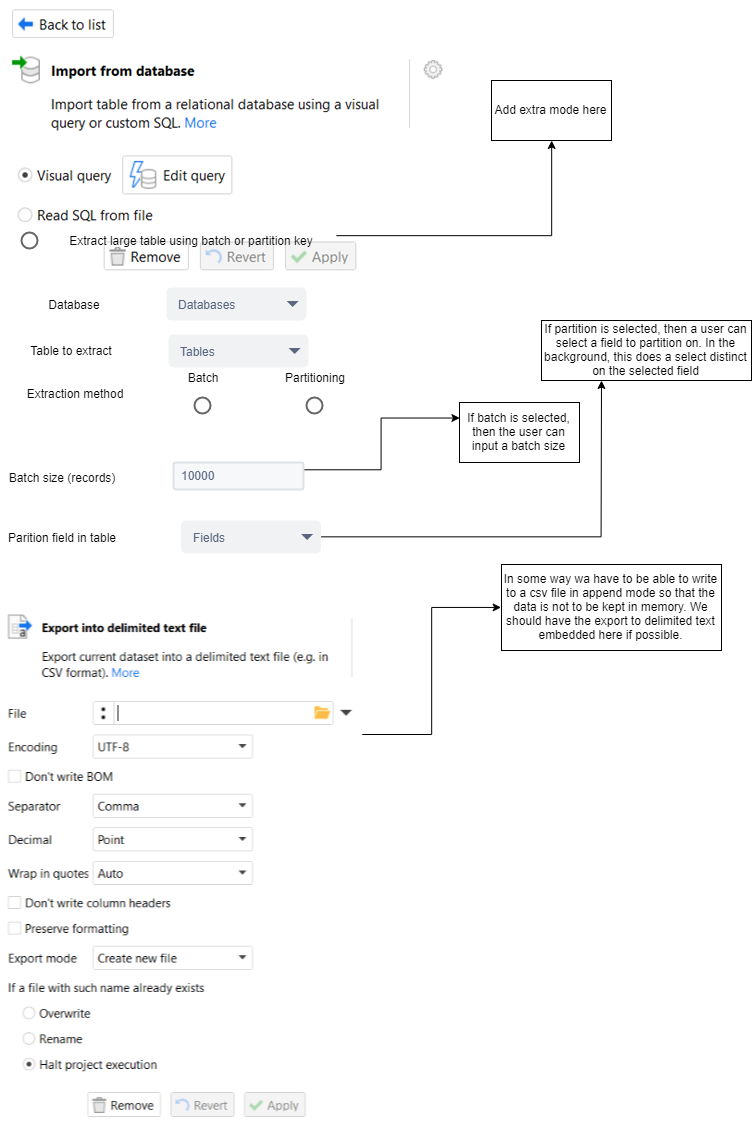
This could be a first idea.The extra fields only are available if one selects the option to extract a large table.
I will send you the XML from draw.io because I cannot upload it here (extension not allowed). Maybe you could adapt it with your input.
1 Like