Hello,
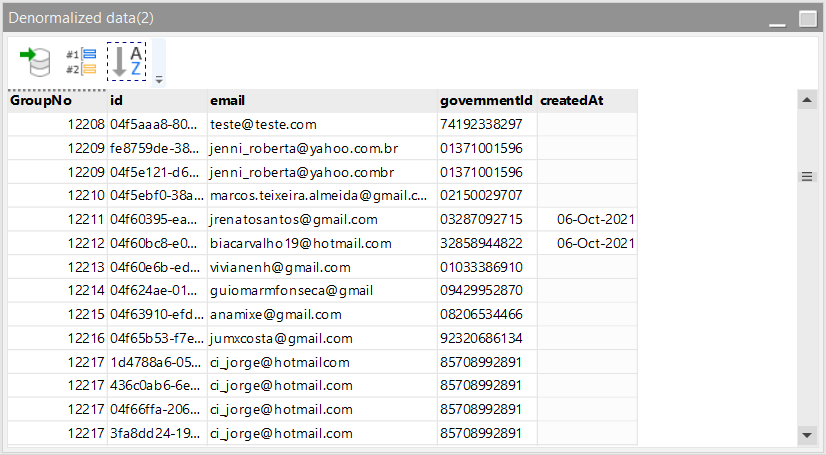
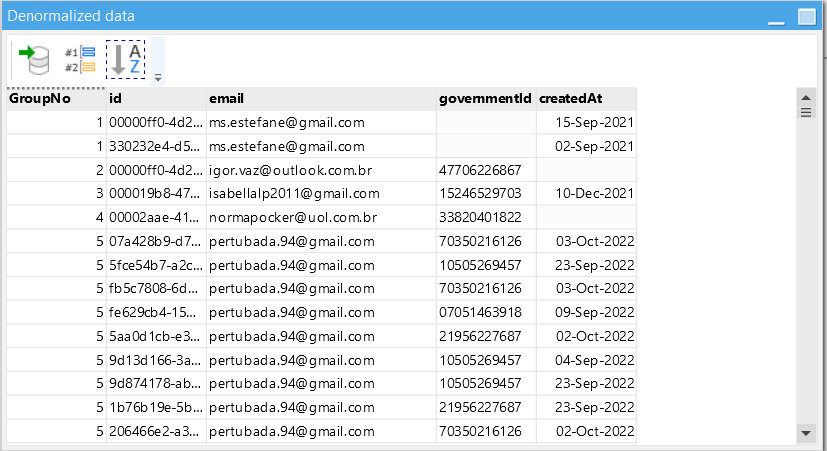
I’m trying to handle some duplicated column values within a table. This is the situation, the table that I’m importing the showing data have the columns “governmentId” and “email” as non-unique values. But the newest table that I’m sending the data to uses these columns as unique.
So I have a bunch of duplicated “governmentId” and “email” duplicated values. I can’t just delete these duplicated records cause this table’s ids are being used as foreign keys in another table.
So far I was deduplicating the table, then importing all the data on another table, filtering to get the non-duplicated records ids on the other table. So in one table I have the non-duplicated records, and the other one has the records that should look up for the matching “email” or “governmentId” and use its id.
I came to a solution that I need to create a new column, that will contains non unique uuids, which some of them are the ones that I got with the deduplicated method using the value on the id, and the other ones, are the duplicated records that should look up the non duplicated table, find the matching “email” or “governmentId” and use its id, passing it to the new column-
Although this may seems messy, I didn’t figure it out a better solution. Now I’m trying to get the duplicated records and match them with the ones in another table in order to get its id.