Hello Community
I'm struggling how to find distinct rows in a given dataset where the row has one or more empty colums/fields. The empty field can vary from row to row. And the data set e.g. Excel or SELECT * FROM [xxx] can variate from each run so the number of coulms and names will be different from time to time.
The case is to do data quality reporting and find incomplete rows in datasets.
The Meta Data function is great but gives the info of which colums have empty values and the same rows can be counted multiple times.
I need to see the distinct rows with issues.
Thanks in advance.
Enjoy your weekend
John Finderup
Hi John,
You can use the "Deduplicate rows" action to only keep distinct rows. Then use "Table metadata" to find columns with empty rows.
Hi Dmitry,
Thank you for your fast answer even during the weekend.
I'm aware of the table metadata action and find it great.
My task though is the opposite. I need to find the exact rows that contain empty fields, one or more, and these fields can be in any column and differ from row to row.
The data can have up to 100 columns but often approx 60.
My bad, I wasn't attentive enough.
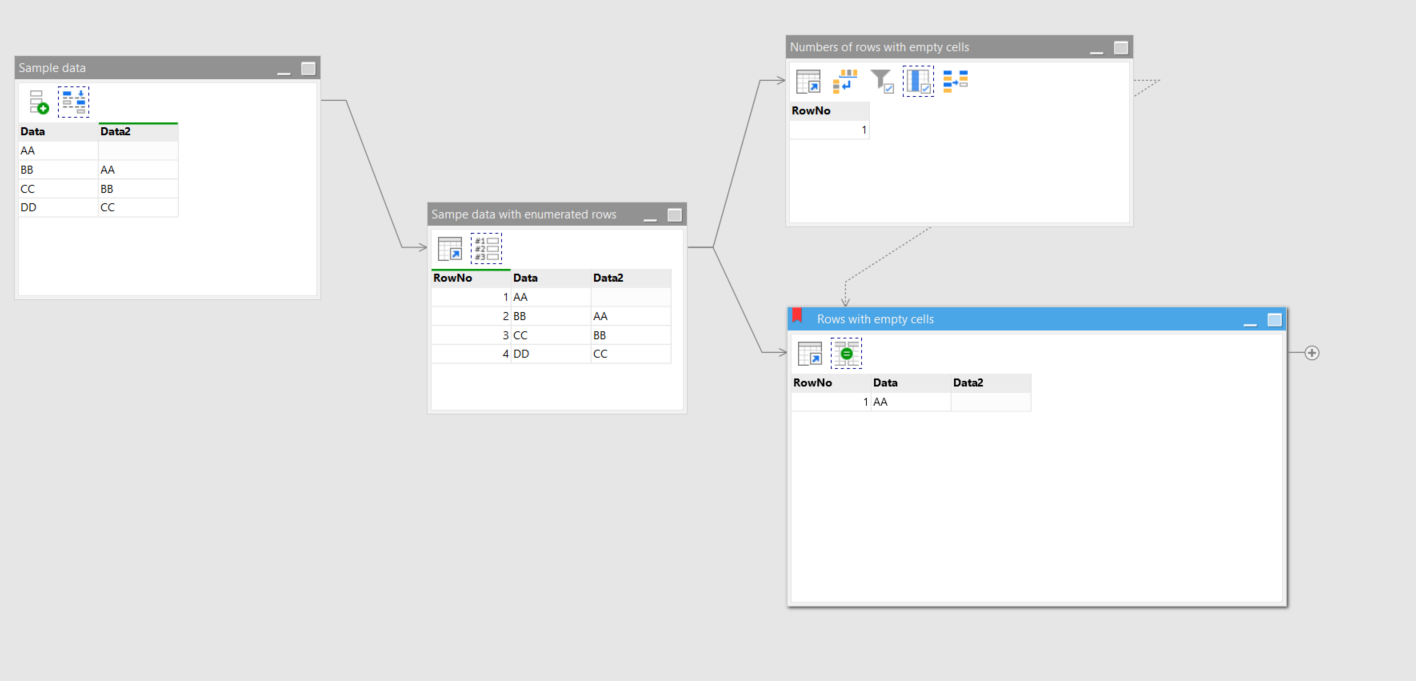
As a rule of thumb, once you need to do something with all columns and their order and existence are not determined, the table needs to be unpivoted first.
The example below shows how to find rows with empty cells no matter how many columns there exist in the source dataset.
rows with empty cells.morph (4.5 KB)
1 Like
No Problem.
Our challenges can sometime be hard to describe - I could also have made a drawing,
I new there was a trick and the one you attached here is spot on - nice neat and elegant - Thanks.
Enjoy our Sunday
BTW It is "Any given Sunday" today - Enjoy the game if you are into Super Bowl - Even thou the US version of football is not big here in EU/Scandinavia there are some fans that are into a late night.
1 Like