This is more of a best practice and/or EasyMorph approach topic.
Business Workflow
Read from web API source GPS breadcrumb data for many vehicles with each vehicle having many updates
Transform the data to make sense to the business tables
a. Header table for last known location
i. One row per asset
b. Detail table for all breadcrumbs consumed.
i. On asset many rows
ii. May have already read the breadcrumbs previously so ignore if the same
iii. Database table has a unique index to prevent duplicates.
Workflow is executed every 15 minutes
The good news is that I have this already working using the easymorph platform. I learned a great deal of how the platform works but I still to learn more. Hence the reason for the question.
Current Approach
Read from api
Keep/remove columns.
Rename columns.
Rule logic to control country name.
Calculate columns.
a. Mostly to deal with combining adding some constants
Fix dates to match database columns
a. Did I mention I hate date logic for all databases. Laughing
Update the asset header table with last know location from ingest.
a. Works perfectly
For some reason have to adjust dates again after the update
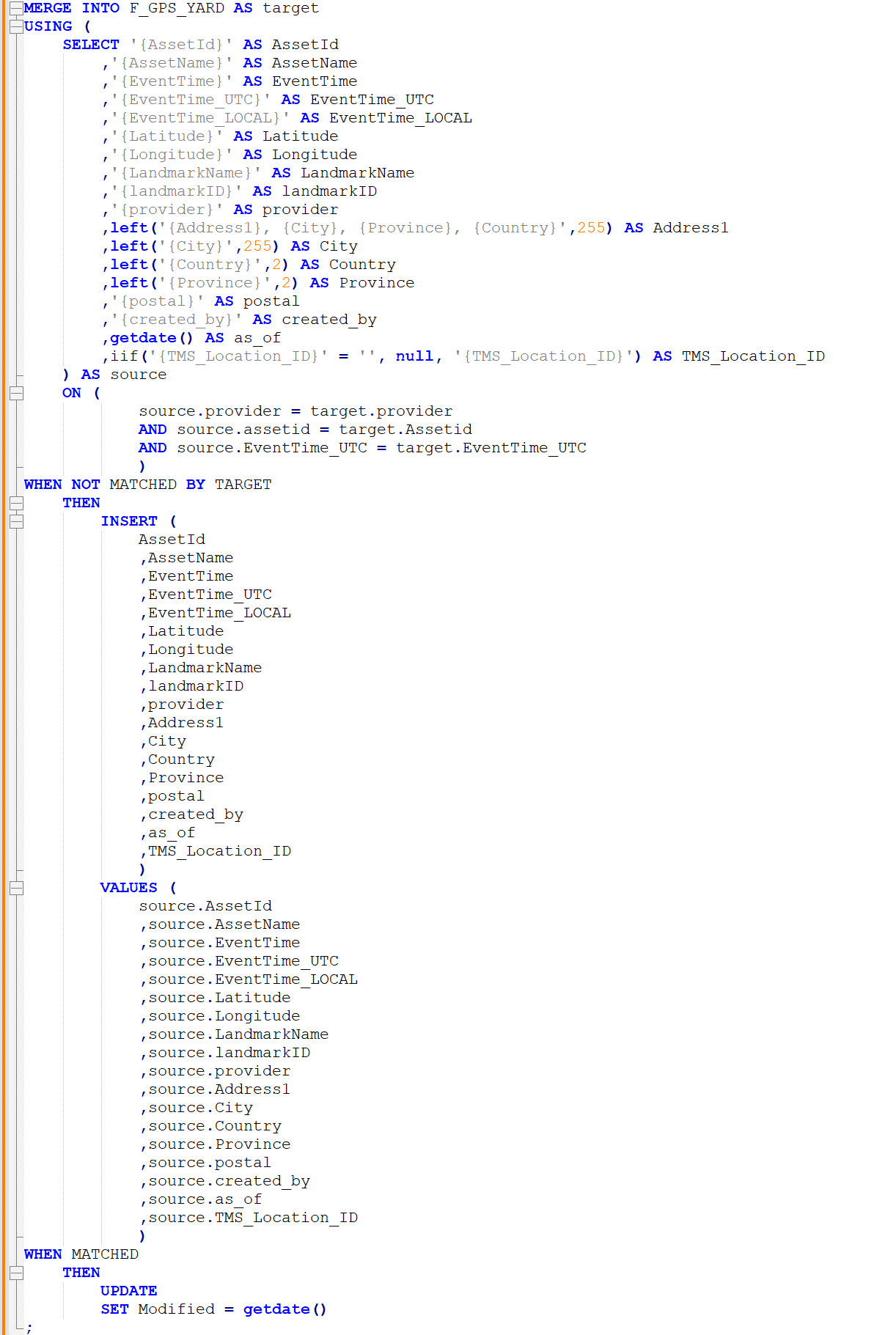
Then iterate through a module (Merge_F_GPS_YARD)
a. This is the one that is very large and will update the duplicates with just the updated date
b. Then inserts new rows
c. To achieve this I used a custom SQL statement this Merge into statement that goes row by row
d.
It works and it is fast. So great news. Again, learning the platform and looking learn more.
The Ask
I have created a unique index on the larger table and just wanted to “Export to database” on mass. When I did this, and the entire input table was NEW and not in the table it worked fine. As soon as one row was duplicated, I just wanted easy morph to ignore the error and keep going to the other row. However regardless of what flags I flipped I was not able to get easymorph to insert into the table just the new rows. The whole batch was ignored.
I wanted to use the database engine to just deal with the inserts and have the duplicate rows ignored.
So does the easymorph community have any suggestions for the newbie. Now remember, the export to table has 10’s of millions of rows so trying to get a temp table of potential matches is a costly sql call. So the “merge into sql statement” achieves the goal. On the update it just updates the modified row date and the insert works fine
the Net/net is that I have it working but would love to learn a cleaner more effective approach that leverages the tool more.
So for now, a fool with a tool is still a fool. That fool is currently me.
to remove duplicates there is deduplicate action in easymorph, if you want deduplicate with particular logic then use aggregate, use enumerate grouping by combination of fields and sorting or use unpivot and pivot
if source table has large amount of data it might be better to create a temp table in server and use bulk insert to the temp table then use the merge query in the server against the temp table (after each merge query runs you can truncate the temp table)
Check out the "Select matching database rows" action. With its help, you can get a list of IDs that already exist in the database table AND in your EasyMorph table. Then remove them from the EasyMorph table (e.g. using "Keep/remove matching rows"), and export the rest of the rows into the database without a conflict.
I am coming at this again and I am getting the "flow" wrong. I know what I am trying to do but not sure how to get it to work.
System A (AS/400) builds a table set with 50 rows. 47 will be updates and 3 witll be inserts
System B, (MysSQL datawarehouse) the reciever has 500,000 rows and is growing.
So I run the action 'Update database table" and 47 rows of system b will be updated
I then try to configure "select matcing data rows" from system be. I would expect this to return the 47 rows I just updated. However, everytime I go to configure the action, it says my input dataset is empty.
How do "set this up". I do fetch from system B all matching rows from the easymorph table. Was looking for an example and I am lost. I am missing a step to inform the action of what dataset to use.
Can you point me in the direction of what I am doing wrong.
You have to put the action behind the actions of the other table. As your screenshot shows, you inserted the action in a new table. Just drag and drop it into the table (DTAMIDR…) in the background at the desired position.
Source A is an AS/400 where I get the batch to validate for update or insert
Target B is a mysql database that will take the updates and potential inserts.
So I read from A, then do drag and drop on that result. I do not understand drag and drop either. Drag and drop the action?
Sorry for the basic questions but I am not sure I understand the placement of the action after I read from the source.
I've built a "mockup" workflow that does upserts. The idea is to use the "Select matching database rows" to obtain a list of asset IDs that already exist in the MySQL table. Then use the list to split the dataset from AS/400 into two derived tables - one table should only contain existing records (they will be updated), and the other table should only contain the new records (they will be inserted).
This is very helpful and matched my thinking. I had to load the new version. Not sure when the to-do action arrived but I was impressed with your use of it. Great way to document and build a complex workflow in stages.
First, I want to thank the community for the great support. Through the information you provided Joschen and Dimitry I have figured out what I was doing wrong.
The actual drag and drop was the key but I was missing the context of it.
So you created the dataset that will be used as the source for the matching and literally drag the action "select matcing database rows" onto the dataset. I was clicking add action and hence it was creating a new action with NO CONTEXT of input.
The user action of dragging the action on the datasent BOUND the source and then I could add the target matching database.
So in this case the source is an easymorph derived table, I then dragged the action onto the dataset and it bound it as the source.
I then told it what to match in the target database of mysql.
So again, thank you. It was a user interaction problem that was me.
This has greatly improved the performance of my workflow.