The Data Catalog is a feature of EasyMorph Server. However, for the purpose of beta-testing, you don't have to install EasyMorph Server. Instead, we've made a public demo site that is available at https://demo.datacatalog.com.
Configure the test environment
1) Request a demo account
Send me a DM (direct message) here on this forum to obtain a demo account. The demo account is a Server space (with password protection). Note that in the production version, the Data Catalog will only be available for spaces with Active Directory authentication (for licensing purposes).
Test spaces are isolated from each other using Server workers that run under different Windows accounts. Beta-testers can't access files of each other.
2) Download EasyMorph Desktop v5.2 (BETA).
Here is the download link: Download EasyMorph Desktop v5.2 (BETA)
Trial key valid until May, 31st: EasyMorph.zip (you will need it if you install the beta under a different Windows account)
To avoid overlapping with an existing EasyMorph installation, it is recommended to install the beta Desktop under a temporary Windows account on your machine, or on a machine without an EasyMorph installation.
Certain features of the beta version may not work correctly. Don't use it for production data or workflows.
3) Configure Server Link
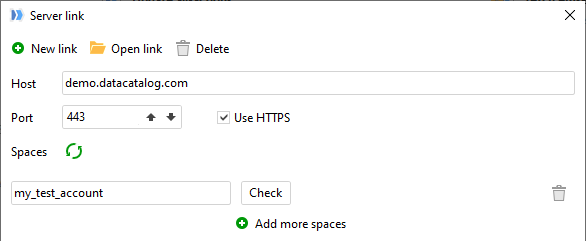
Configure Server Link to point to demo.datacatalog.com, use HTTPS, port 443.
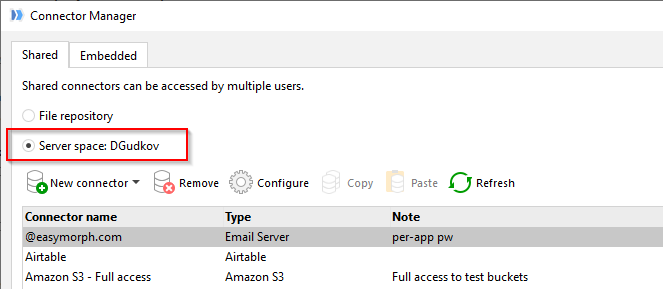
Also, configure your Connector Manager to use connectors from your test space:
Data Catalog overview
The purpose of the Data Catalog is to simplify access to various sources of business data and provide means for access audit and governance.
Data Catalog has a hierarchical folder-like structure of directories. Each directory contains catalog items and/or other directories.
Note that catalog directories are NOT subfolders of the Public folder (tab Files). The directories are a separate data structure that is stored in an internal database and not accessible externally.
Catalog items can be of 3 types:
- Datasets
- Files
- URLs
In turn, each of the item types can be static or computed (using an EasyMorph workflow). Therefore, in total there are 6 item types:
-
Static EasyMorph datasets - regular .dset files stored in the Public folder of EasyMorph Server.
-
Computed datasets - EasyMorph datasets computed dynamically on the fly using a published project stored in the Public folder of the Server. The result table of the project is the resulting dataset.
-
Static file - any file stored in the Public folder of EasyMorph Server. For instance, a PDF file.
-
Computed file - a file stored in the Public folder. The relative path to the file is computed dynamically on the fly using a published project stored in the Public folder. The first value of the first column is the resulting relative path to the file.
-
Static URL - any URL (e.g. a hyperlink to a PowerBI report)
-
Computed URL - a URL that is computed dynamically on the fly using a published project stored in the Public folder. The first value of the first column is the resulting URL.
As you can notice, computed URLs and files paths use the top (first) value of the first (leftmost) column. Example:
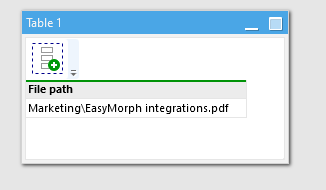
If the result dataset has more columns/rows - they are ignored. The first column name doesn't matter.
Since computed items (datasets, files, and URLs) use a project to calculate its result, project parameters can be specified before retrieving a computed item. This makes computed catalog items somewhat similar to Server tasks. However, they are not Server tasks. The Catalog is a separate feature of EasyMorph Server
More item types will become available in later releases.
Working with the Data Catalog in Desktop
EasyMorph Desktop now consists of two integrated applications - Workflow Editor and Data Catalog. You can switch between them in the app bar, introduced in version 5.2 (see below). The Workflow Editor is what EasyMorph Desktop was prior to v5.2. Let's look closer at the Data Catalog part:
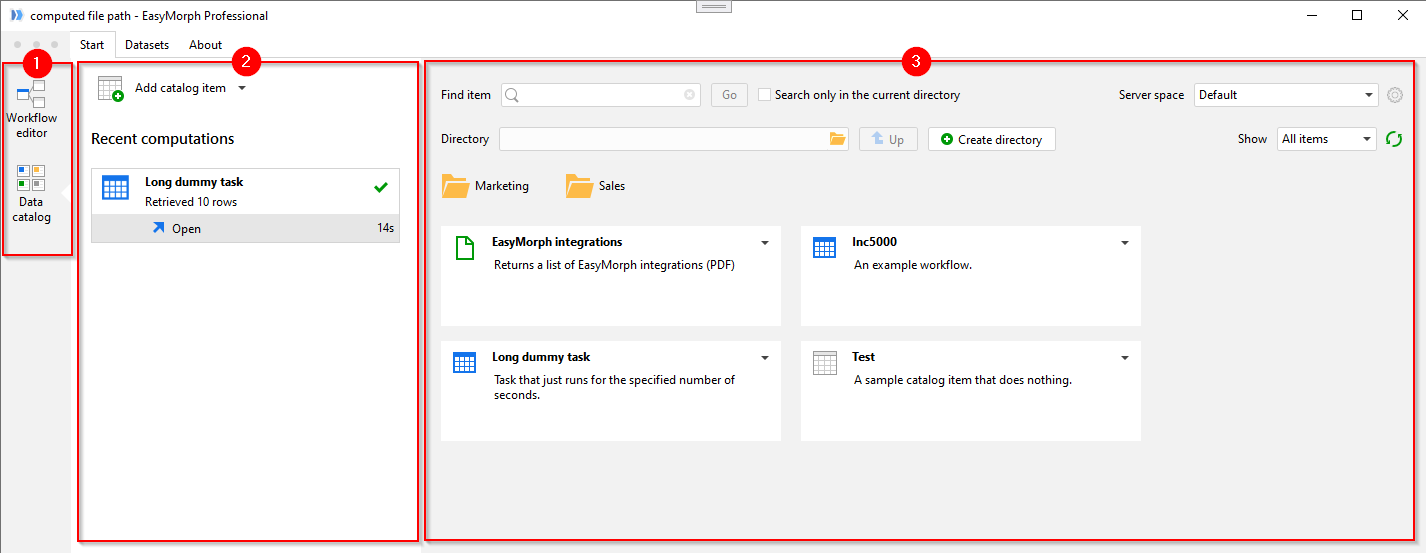
The app sidebar (1) is where you switch to the Catalog. It's been introduced in v5.2.
The "Recent computations" sidebar (2) shows the recent computed items. Note that static items aren't displayed here.
Finally, the biggest part of the screen is occupied by the catalog browser (3). Here is you can browse directories and sub-direcories, create new directories and catalog items, and retrieve items.
Let's look closer at a catalog item:
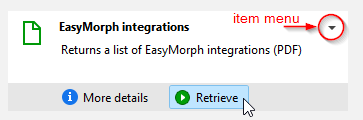
When hovered with mouse, it reveals two buttons - "More details" and "Retrieve". The former displays a dialog with more information about the item (such as annotation or related items). The latter retrieves the item.
Retrieving items
What happens when you press "Retrieve" depends on the item type:
Retrieving a dataset will download it to your machine and open it in the Dataset Viewer (more on that below).
Retrieving a file will save it to the specified folder on your machine.
Retrieving a URL will open the URL in the default web-browser on your machine.
Parameters
When retrieving a computed item, you may be prompted to provide parameters first. Note that parameter annotations are displayed as well.
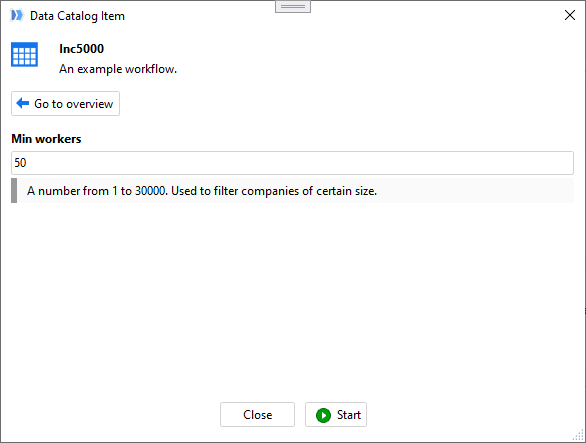
When a catalog item is created/edited, parameters to enter should be explicitly selected from a list of available project parameters. By default, computed items have no parameters.
Dataset Viewer
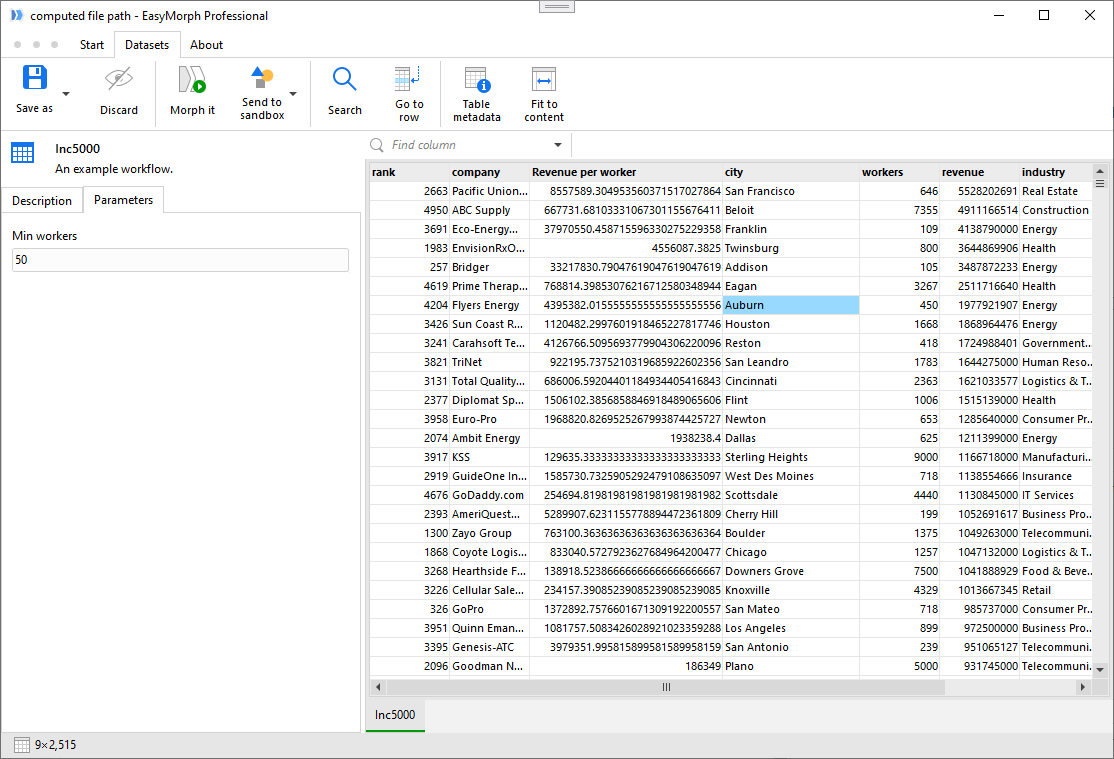
The Dataset Viewer displays retrieved datasets, computed or static. In the Viewer you can:
- View dataset
- See dataset metadata (unique counts, etc.)
- Find values
- Send dataset to a sandbox (new or existing) in Workflow Editor
- Save dataset in a supported file format (csv, xlsx, dset, etc.)
- View catalog item details (description, related items, parameters, etc.)
- Discard dataset from memory
The Dataset Viewer can keep several datasets open. Since all of them are stored in memory, make sure to discard large datasets when they are no longer needed to avoid running out of memory.
Adding catalog items
Adding catalog items is done from the start screen of the Catalog.
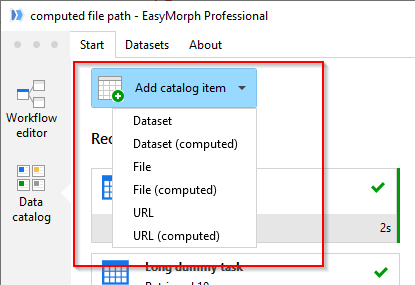
Note that if you are creating a computed item, you will need to create a corresponding EasyMorph project first, and publish it to the Server. Then, when creating a computed item, you can specify the published project in item settings.
Item fields
It is possible to describe fields of each item, be it a dataset or a file (e.g. a PDF file). These fields are searchable - you can find an item by a field. In the initial release, item fields should be created manually. In later releases, we will add tools for automated field creation/editing.
Working with Data Catalog in the web UI
After logging in EasyMorph Server, the Catalog is available in a new tab unsurprisngly named "Catalog".
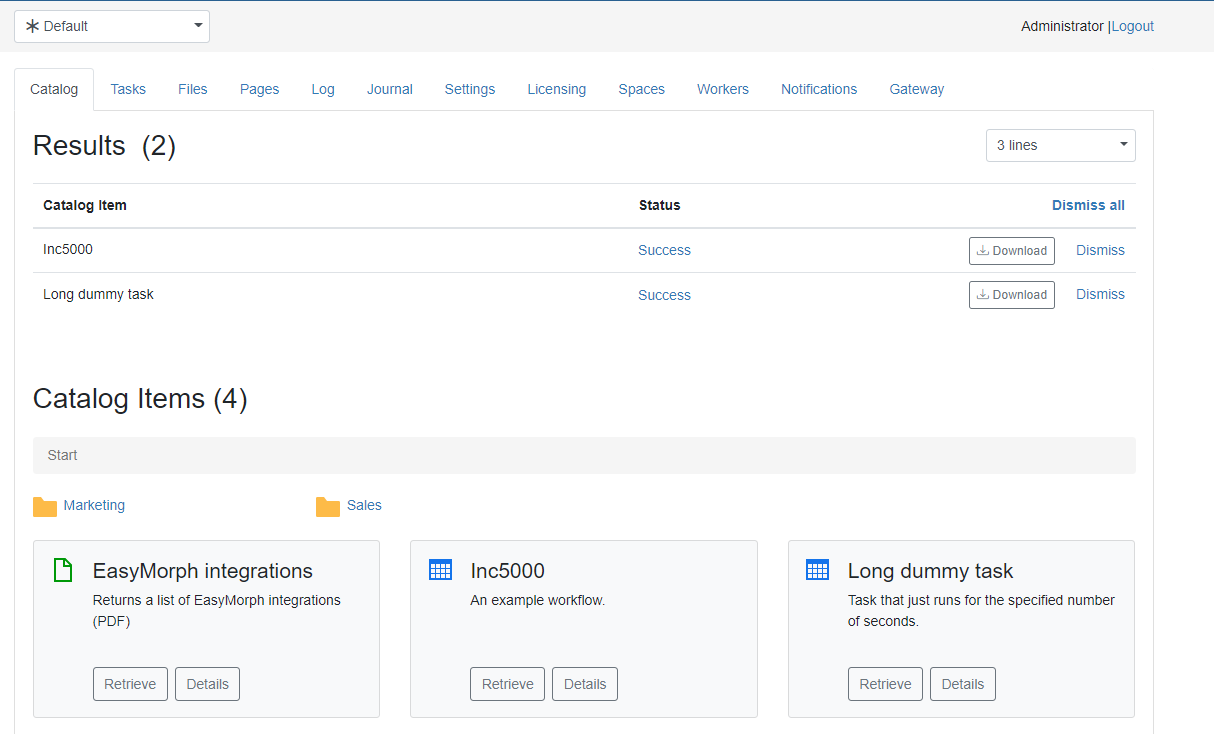
From the web UI, it is possible to view item details and retrieve items (computed or not). Note that viewing datasets is not possible from the web UI. Retrieved datasets will be available for downloading and further viewing locally in EasyMorph Desktop.
Retrieving files and opening URLs works as expected.
Journal
Most operations with catalog items are recorded in the Server journal. Therefore you can view who accessed what item and when.

Accessing Server journal of the public demo site is not possible for beta testers. If you would like to test journalling of catalog operations, request a Server installer of v5.2. from our support.



