This is not really a feature request as much of as a hmmm, what do you all think? Would something like this be going to far?
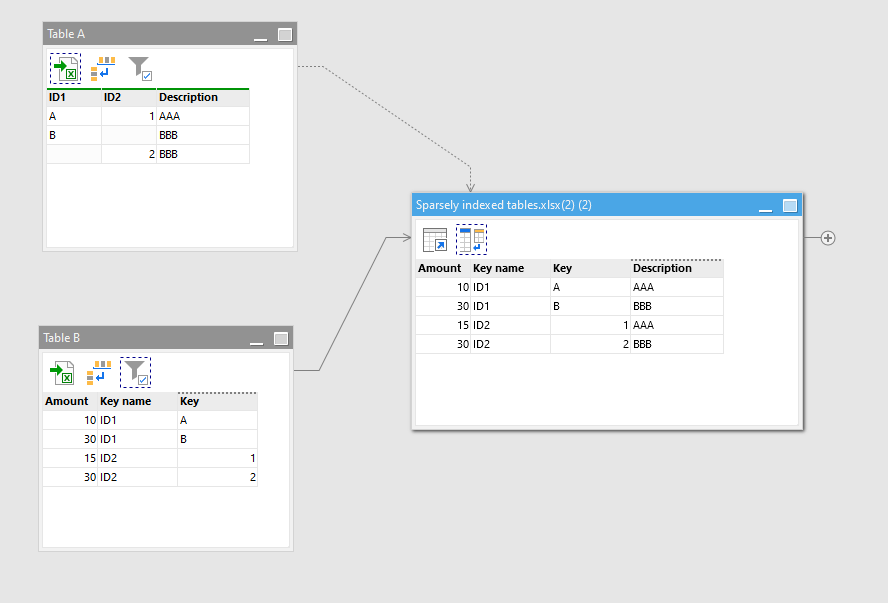
Basically what I am thinking is of the merge/join actions, where the matching criteria are set between the two tables, what if you could have a second or third set of rules for the match to perform on in the event the first criteria fails? Kind of like how we set up the conditions on the rules action but those conditions instead end up being the join criteria.
Currently in Easymorph, you would need to perform a second merge action to get the records from another table that didn't match in the other table. And that would bring a second copy of all the columns over if you had successes after the first merge attempt. Then you have to do a bunch of cleanup on the columns to normalize back to just one column per joined attribute. I guess alternatively, you could do some filtering on scenarios that are simple, like empty cells that are kind of like attributes of the composite key you are making for the regular merge criteria, but things get squirrelly really fast.
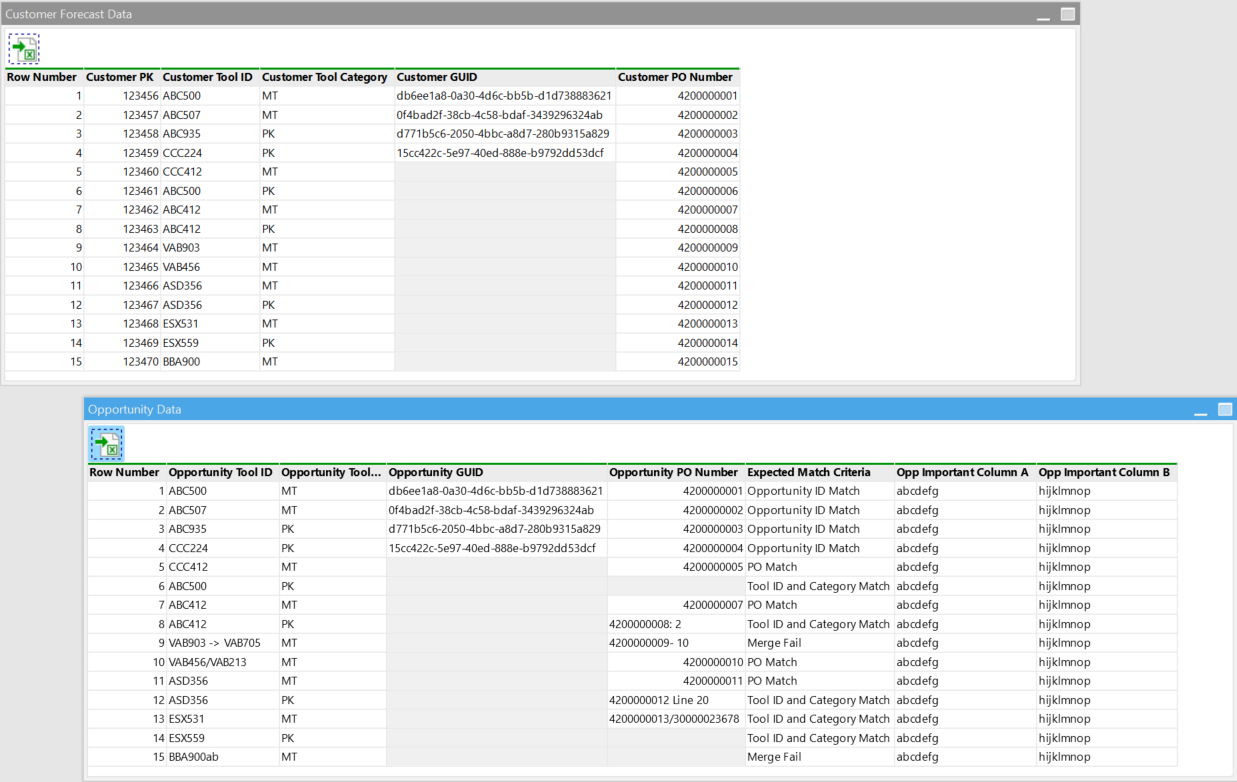
Here is an explanation of the use case I have for such a feature. My company has a CRM system that is used to log customer orders but the data entry is done by various stakeholders and business units. There are silos of entry method between for different business units as well as business unit customer combinations. Sometimes a PO number field will be input without the line id. Sometimes the customer's tool id name is entered in differently than what the customer calls it but the PO is correct. I've tried normalizing for different methods of "manual key value input" but it only goes so far. For example, I did cleanup on various methods in which PO values are input and came up with 42 different rules. Someone is always going to come up with a new way to enter something that hasn't been done before and break a cleanup rule. But, there is a decent chance among several different matching criteria I can back into a combination that will give me a proper join.
Anyway, sorry if this idea is way out there. I was just brainstorming a bit while working through some reporting I am doing for sales.
Also, the new profile feature and the merge action is amazing. I am really loving it so far. I am actually going to use the visual it provides in a meeting to encourage some operational behavior changes. I have built error type tables to isolate join failures etc before but it never conveys well to the business folks. Now with this tool I can take a screenshot and have a proper conversation about it visual with colors that operations managers will understand. And the added bonus of being able to pop out the records into a sandbox is icing on the cake.
As always, thanks Easymorph team!
Best wishes,
Perk