Is there any way to cache a project file so it doesn’t have to run all the actions when I load it?
I’m loading quite a few large data sets with 620 actions and it can take 10 mins for the Project to load.
I have quite a few of these projects as we’re experimenting with different workflows, and as I had my first EasyMorph crash yesterday I don’t want to load more than a couple of Projects at a time!
That means I spend quite a bit of time waiting for Projects to load.
Is this a limitation of only using the Desktop version? Does the Server version get around this?
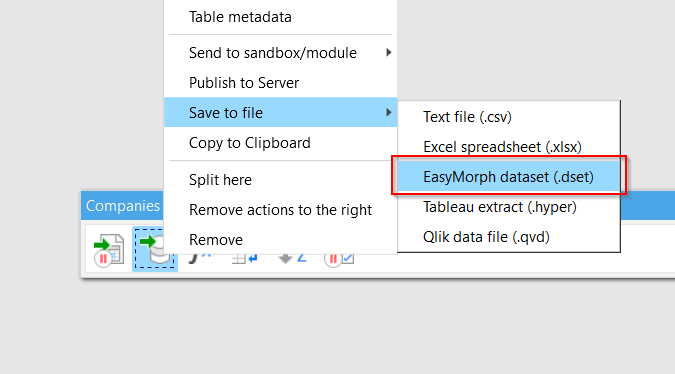
I am going to re-save the data in the EasyMorph format to see if that speeds things up - might make this a mute point!
Just as a reference for others, it takes EasyMorph 2’33" to load CSV that has 24 columns and 20,803,095 rows - this is very quick compared to other data manipulation software I’ve used, even on much smaller data sets - I’m looking at you Excel and Power Query!
In native EasyMorph format it takes a about a second! At first I thought I was still looking at my original CSV input!
I saved all of my source files in the native EasyMorph format, and also changed the various files that are created for iteration processing in the native format, and a process that took 2 days or more using a “traditional” import into database and then processing from there takes just over 12 minutes!
Some more metrics!
Totals source CSVs - 36 - 16.1Gb - approx 100 million rows across 28 columns.
Total source .dset - 36 - 2.87 Gb - same data!
Using only CSVs (import and export to files to be iterated) the process takes just over 20 minutes - not a massive difference, but if we’re running this process for hundreds of clients it makes a huge difference.
Using the native files also means a project that can take over 10 minutes to load because it’s importing all the CSVs takes about 30 seconds using .dset files - ridiculous!