I have a list of transactions and I need to adjust entries based upon future transactions. I have a routine that works by using Iterate Table transformation, but it only works well on hundreds of rows, not the potentially millions that are needed.
The problem seems to stem from the fact that the routine needs to return a value for the current row and also mark the future row as being used. I do this by keeping a table of credits and importing/exporting the table in the subproject. If there was a way to return a modified table from a project, instead of appending the rows, I think that might help. The table sizes are too large to append the entire set for each loop.
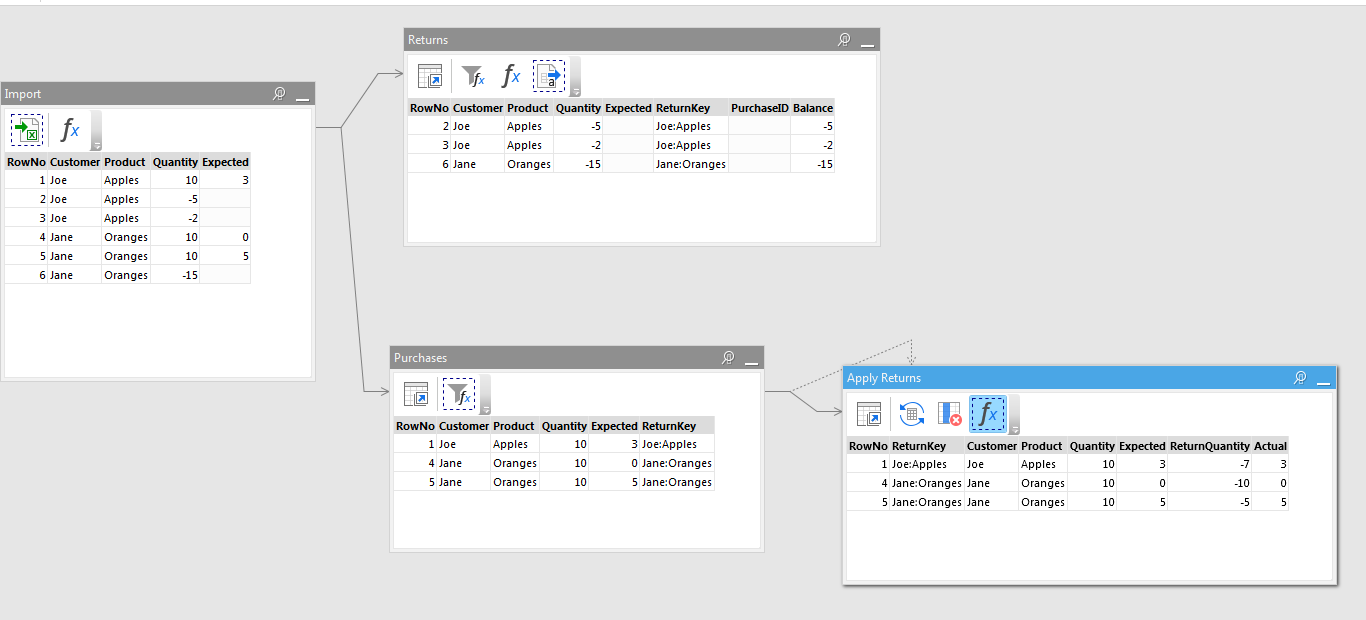
In this example, Joe bought 10 apples and then took them 5 back to the store in one transaction, and another 2 in another transaction. That leaves his original transaction with 3 apples.
Jane bought 20 oranges total, in two transactions, and returned 15 in a transaction. That leaves her with 5 oranges on her original transaction.
Is there another way to solve this problem that performs well?
the pattern for using iterations in general is to split a large dataset into small chunks, then process one chunk in one iteration, then append processed chunks back into a result table. When arranged right, iterations should not append the entire dataset multiple times.
The pattern for using Iterate Table is to pass entire table into the iterated table and then filter it using a parameter (assigned from the calling project) in order to obtain a chunk to process.
In your case:
The source table for iterations is Purchases.
Each chunk is defined by ReturnKey.
The task is to take the total return for a chunk and distribute it cumulatively across purchases.
Here is how the logic works:
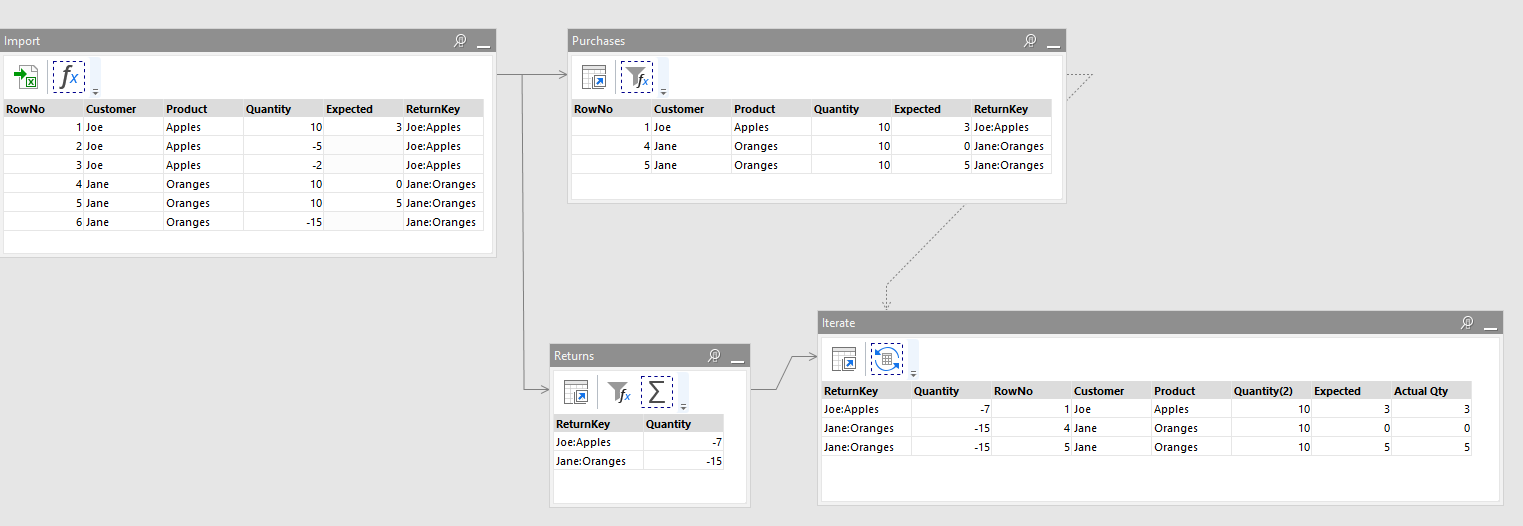
Calculate aggregate returns for each ReturnKey.
Filter out returns to keep only purchases.
Iterate: for each ReturnKey distribute aggregated return across purchases for this ReturnKey. To speed up things we use Iterate Table to pass table Purchases in memory. ReturnKey and total return amount are passed as parameters.
In the iterated project:
In each iteration table Purchases is filtered using ReturnKey (which is different on each iteration) in order to keep only purchases for that ReturnKey.
Use Running Total and Rule transformations to distribute the total return amount for this particular ReturnKey.
In this case no reading/writing is performed in each iteration – everything is calculated in memory so performance should be good.
In your example you created returns.csv in one derived table, but it was used in iterations in another derived table independent from the first one. EasyMorph calculates independent tables in parallel (asynchronously) when possible. It means that iterations could start earlier than returns.csv is ready which would cause an error. To deal with such cases there is the Synchronize transformation. See this blog post for more details: Using synchronize transformation.
I suspect iterations might be not necessary at all in this case because the Running Total transformation supports grouping. But I didn’t try it.
In my variant I assumed that all ReturnKeys had a return, which might be not the case in the real-life scenario.
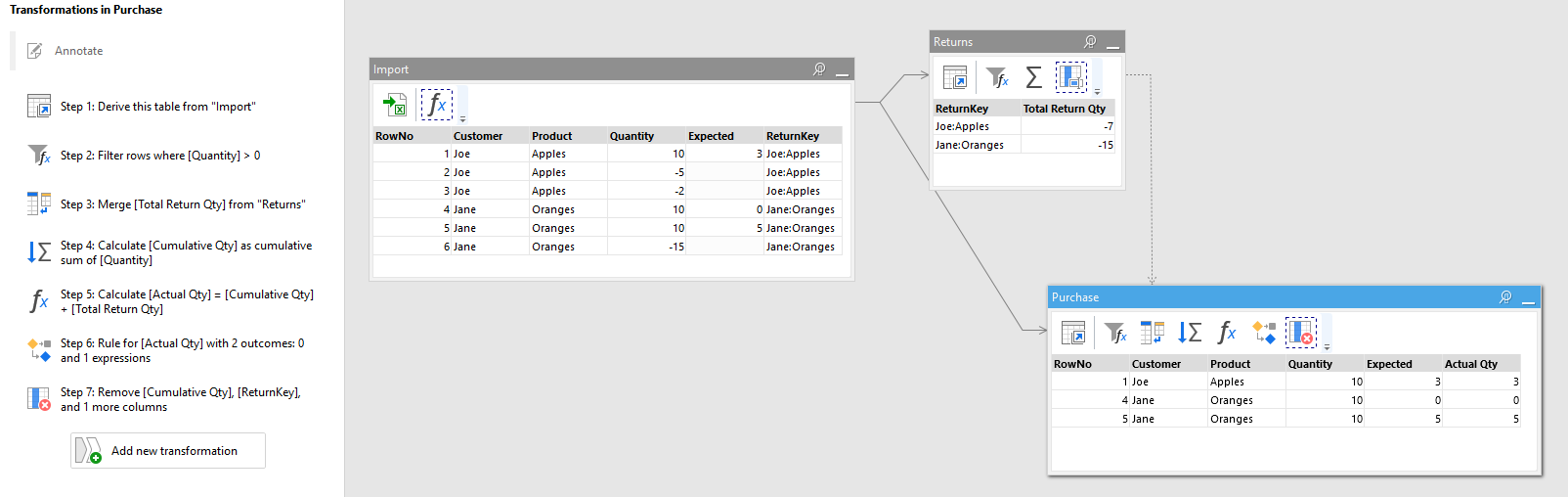
It looks like for this particular task iterations are not needed at all, indeed. Here is a solution that doesn’t use iterations, only Running Total with grouping.
@dgudkov Thank you! Your iterate version was still too slow on production data (2 million rows with 40,000 returns), so I killed it after 15 minutes. Currently our T-SQL procedure runs in about 2 minutes (uses cursors). The new version runs nearly instantly and seems to produce the right results. I’m still comparing but so far so good.
Old habits of using looping can be tough to break out of when there’s a new paradigm of array thinking. Examples like these help develop the skill set.