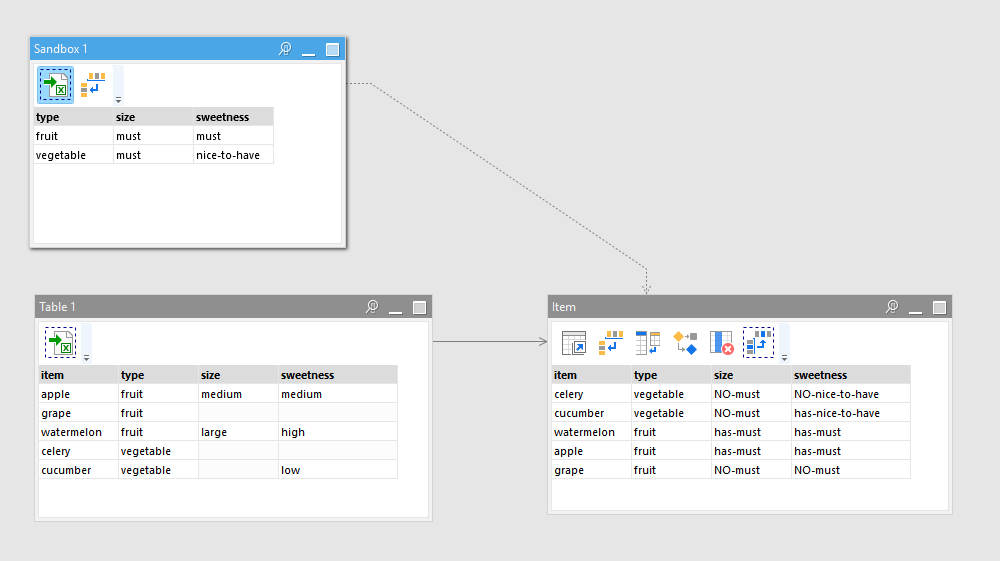
I have two tables:
- An item table (that may be incomplete — one column is “type”)
- a type table (that defines what fields should be defined for different types of items)
To simplify, let’s say the item table has various foods like so (note that it’s intentionally incomplete — the whole point of this exercise is to determine where someone has to go through and classify the items further):
item, type, size, sweetness
apple, fruit, medium, medium
grape, fruit, ,
watermelon, fruit, large, high
celery, vegetable, ,
cucumber, vegetable, , low
And a type table for type of food (in this example: when classifying food, we don’t really care about the sweetness of vegetables since they’re not very sweet):
type, size, sweetness
fruit, MUST, MUST
vegetable, MUST, nice-to-have
What I would like is to have a resulting table like so:
item, has-size, has-sweetness
apple, has-must, has-must
grape, NO-must, NO-must
watermelon, has-must, has-must
celery, NO-must, no-nice-to-have
cucumber, NO-must, has-nice-to-have
Then we could do interesting things like calculate the percentage of fruits that have any NO-must values (those fields that must be filled in by someone).
To further complicate this, let’s assume there are a lot of columns. And that the columns may change. In other words, we do NOT want to literally create a calculated column for all these values (which would be easy in the example above).
Ideally it would be possible to add an action that works like so:
- Looking up by type…
- for every column with the same name in the item and type table (ideally NOT explicitly enumerating them all)…
- if it’s “MUST” in the definition but has no value in the item table then set new column has-<column_name> with value NO-must, otherwise set to has-must…
- and similar logic for nice-to-have and blank
Is there any way of accomplishing this sort of thing?
Thanks,
— David