Hello Reinhard and welcome to the Community!
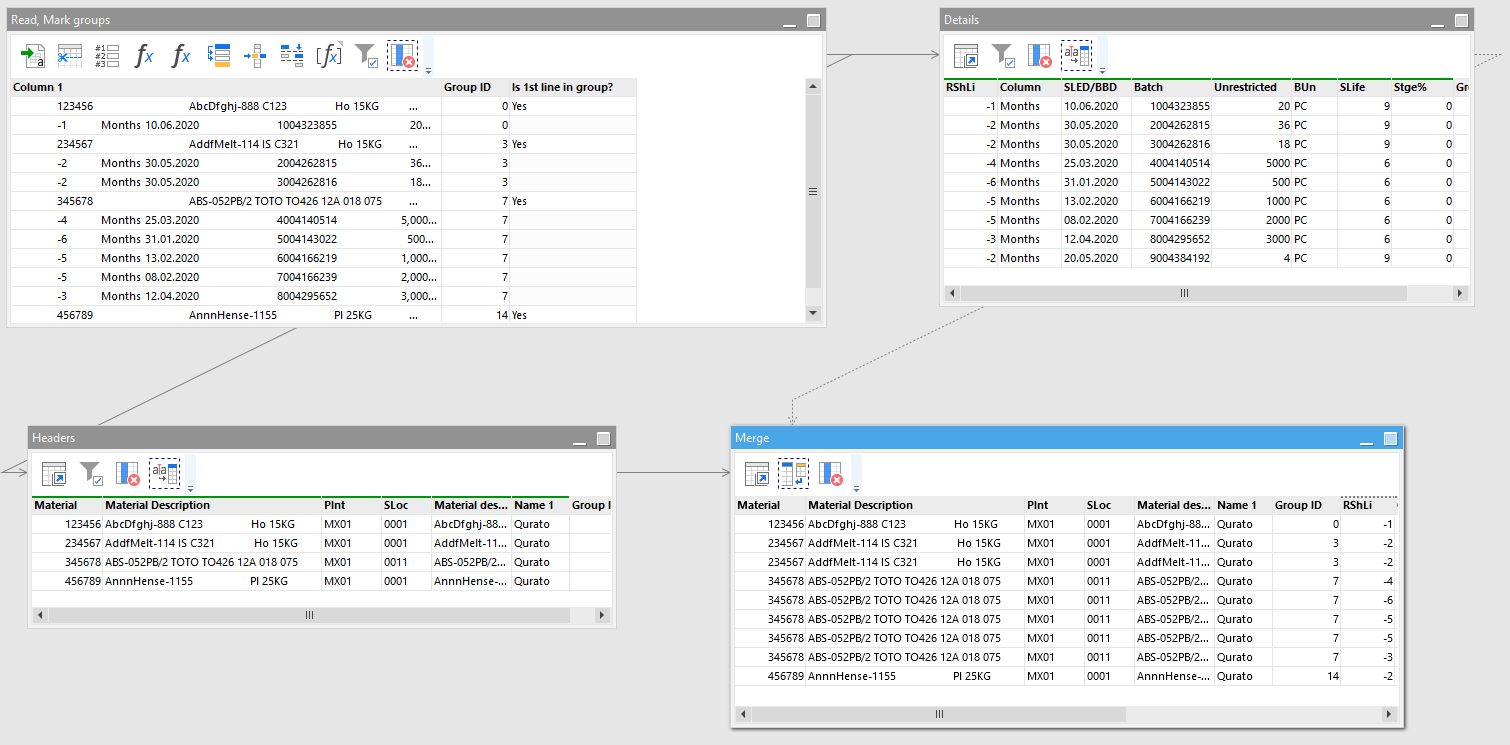
The source file can be classified a sectioned file where each section is a sequential group of rows. Sections are separated by empty lines. In each section the first row is the section header. The rest of rows is the section details (body). Headers rows and detail rows are fixed width text, but column names and widths for headers are different from column names and widths of the detail rows.
The result table contains the sections in which header data is merged with the detail (body) data.
As we’ve analyzed the file structure, the transformation algorithm would be as follows.
- Detect empty lines
- Identify groups as sequential rows between empty lines
- Mark the 1st line in each group
- Split group headers, and group details into 2 derived tables. We need to split them into 2 tables because they have different sets of columns and therefore should be split differently. We keep group IDs in each table, which will help us merge groups back later.
- Split header rows and detail rows into columns in their respective tables
- Merge header and detail data into one table using group ID as the key
- Delete the column with group ID
The project below implements the transformation logic explained above.
sectioned-text-parsing.morph (9.9 KB)
Note that the source text file for this project is slightly modified. I understand that you removed sensitive data from the source file before publishing it in the post. It seems to me that one tabulation character has been removed mistakenly because this broke column widths in one row. Therefore I inserted one tabulation character in order to keep column widths uniform.
Here is the modified source file:
Orgdata 20200707.txt (1.2 KB)